

The deep studying mannequin of Secure Diffusion is big. The burden file is a number of GB giant. Retraining the mannequin means to replace a whole lot of weights and that’s a whole lot of work. Typically we should modify the Secure Diffusion mannequin, for instance, to outline a brand new interpretation of prompts or make the mannequin to generate a unique fashion of portray by default. Certainly there are methods to make such an extension to present mannequin with out modifying the present mannequin weights. On this put up, you’ll be taught concerning the low-rank adaptation, which is the most typical method for modifying the habits of Secure Diffusion.
Let’s get began.
Utilizing LoRA in Secure DiffusionPhoto by Agent J. Some rights reserved.
Overview
This put up is in three elements; they’re:
What Is Low-Rank Adaptation
Checkpoint or LoRA?
Examples of LoRA Fashions
What Is Low-Rank Adaptation
LoRA, or Low-Rank Adaptation, is a light-weight coaching method used for fine-tuning Giant Language and Secure Diffusion Fashions while not having full mannequin coaching. Full fine-tuning of bigger fashions (consisting of billions of parameters) is inherently costly and time-consuming. LoRA works by including a smaller variety of new weights to the mannequin for coaching, fairly than retraining all the parameter house of the mannequin. This considerably reduces the variety of trainable parameters, permitting for sooner coaching occasions and extra manageable file sizes (usually round a couple of hundred megabytes). This makes LoRA fashions simpler to retailer, share, and use on shopper GPUs.
In easier phrases, LoRA is like including a small staff of specialised employees to an present manufacturing unit, fairly than constructing a wholly new manufacturing unit from scratch. This permits for extra environment friendly and focused changes to the mannequin.
LoRA is a state-of-the-art fine-tuning technique proposed by Microsoft researchers to adapt bigger fashions to explicit ideas. A typical full fine-tuning includes updating the weights of all the mannequin in every dense layer of the neural community. Aghajanyan et al.(2020) defined that pre-trained over-parametrized fashions really reside on a low intrinsic dimension. LoRA method relies on this discovering, by by proscribing weight updates to the residual of the mannequin.
Suppose that $W_0in mathbb{R}^{dtimes okay}$ represents a pretrained weight matrix of dimension $mathbb{R}^{dtimes okay}$ (i.e., a matrix of $d$ rows and $okay$ columns in actual numbers), and it modifications by $Delta W$ (the replace matrix) such that the fine-tuned mannequin’s weight are
$$ W’ = W_0 + Delta W$$
LoRA use the method lowers the rank of this replace matrix $Delta W$ by rank decomposition such that:
$$Delta W = B occasions A$$
the place $Binmathbb{R}^{dtimes r}$ and $Ainmathbb{R}^{rtimes okay}$, such that $rll min(okay,d)$$.
Breaking a matrix into two decrease rank matrices
By freezing $W_0$ (to avoid wasting reminiscence), we will fine-tune $A$ and $B$, which include the trainable parameters for adaptation. This ends in the fine-tuned mannequin’s ahead move wanting like this:
$$h = W’x = W_0 x + BA x$$
For Secure diffusion fine-tuning, it’s adequate to use rank decomposition to cross-attention layers (shaded beneath) that are liable for integrating the immediate and picture data. Particularly, the load matrices $W_O$, $W_Q$, $W_K$, and $W_V$ in these layers are decomposed to decrease the rank of the load updates. By freezing different MLP modules and fine-tuning solely the decomposed matrices $A$ and $B$, LoRA fashions can result in smaller file sizes whereas being a lot sooner.
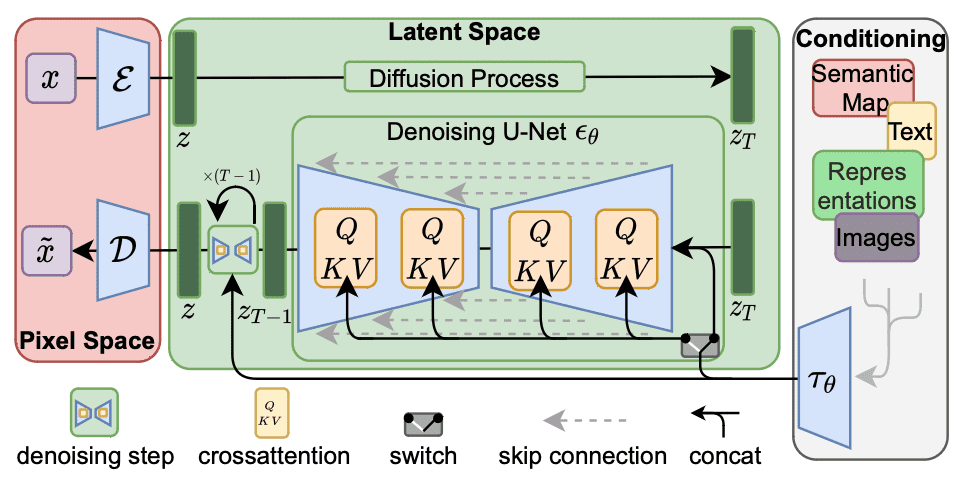
Workflow of Secure Diffusion. The crossattention modules will be modified by LoRA.
Checkpoint or LoRA?
A checkpoint mannequin is an entire, pre-trained mannequin saved at a specific state throughout coaching. It comprises all of the parameters realized throughout coaching and can be utilized for inference or fine-tuning. Nevertheless, fine-tuning a checkpoint mannequin requires updating all of the weights within the mannequin, which will be computationally costly and end in giant file sizes (usually in a number of GBs for Secure Diffusion).
Alternatively, LoRA (Low-Rank Adaptation) fashions are a lot smaller and extra environment friendly. It behaves as an adapter that builds on the highest of a checkpoint mannequin (basis or base mannequin). LoRA fashions replace solely a subset of a checkpoint mannequin’s parameters (enhancing a checkpoint mannequin). This permits these fashions to be small-sized (often 2MB to 500MB) and be often fine-tuned for particular ideas or types.
For instance, fine-tuning a Secure Diffusion mannequin could also be executed with DreamBooth. DreamBooth is a fine-tuning technique that updates all the mannequin to adapt to a selected idea or fashion. Whereas it could possibly produce spectacular outcomes, it comes with a big disadvantage: the dimensions of the fine-tuned mannequin. Since DreamBooth updates all the mannequin, the ensuing checkpoint mannequin will be fairly giant (roughly 2 to 7 GBs) and require a whole lot of GPU assets for coaching. In distinction, A LoRA mannequin considerably requires much less GPU necessities but the inferences are nonetheless corresponding to these of a Dreamboothed checkpoint.
Whereas it’s the most typical, LoRA will not be the one method to modify Secure Diffusion. Consult with the workflow as illustrated above, the crossattention module took enter $tau_theta$, which often resulted from changing the immediate textual content into textual content embeddings. Modifying the embedding is what Textual content Inversions do to vary the habits of Secure Diffusion. Textual Inversions is even smaller and sooner than LoRA. Nevertheless, Textual Inversions have a limitation: they solely fine-tune the textual content embeddings for a specific idea or fashion. The U-Internet, which is liable for producing the pictures, stays unchanged. Which means Textual Inversions can solely generate photographs which are much like those it was educated on and can’t produce something past what it already is aware of.
Examples of LoRA fashions
There are lots of completely different LoRA fashions inside the context of Secure Diffusion. One method to categorize them is to base on what the LoRA mannequin does:
Character LoRA: These fashions are fine-tuned to seize the looks, physique proportions, and expressions of particular characters, usually present in cartoons, video video games, or different types of media. They’re helpful for creating fan paintings, recreation improvement, and animation/illustration functions.
Model LoRA: These fashions are fine-tuned on paintings from particular artists or types to generate photographs in that fashion. They’re usually used to stylize a reference picture in a specific aesthetic.
Clothes LoRA: These fashions are fine-tuned on paintings from particular artists or types to generate photographs in that fashion. They’re usually used to stylize a reference picture in a specific aesthetic.
Some examples are as follows:

Picture created with character LoRA “goku black [dragon ball super]” on Civitai, authored by TheGooder

Picture created with fashion LoRA “Anime Lineart / Manga-like (线稿/線画/マンガ風/漫画风) Model” on Civitai, authored by CyberAIchemist.

Picture created with clothes LoRA “Anime Lineart / Manga-like (线稿/線画/マンガ風/漫画风) Model” on Civitai, authored by YeHeAI.
The most well-liked place to search out LoRA mannequin information is on Civitai. If you’re utilizing the Secure Diffusion Internet UI, all it’s essential do is to obtain the mannequin file and put it into the folder stable-diffusion-webui/fashions/Lora.
To make use of the LoRA from the Internet UI, you simply want so as to add the identify of the LoRA in angle brackets as a part of your immediate. For instance, one of many picture above is generated with the immediate:
greatest masterpiece,1girl,solo,extremely absurdres,hoodie,headphones, avenue,open air,rain,neon lights, gentle smile, hood up, arms in pockets, wanting away, from facet, lineart, monochrome, <lora:animeoutlineV4_16:1>
The half “<lora:animeoutlineV4_16:1>” means to make use of the LoRA which the mannequin file is called as animeoutlineV4_16.safetensors, and apply it with weight 1. Be aware that within the immediate, nothing talked about concerning the line artwork fashion besides the reference to a LoRA mannequin. Therefore you possibly can see that the LoRA mannequin produced an unlimited impact to the output. If you’re curious, you possibly can usually discover the immediate and different parameters used to generate the image from these posted on Civitai.
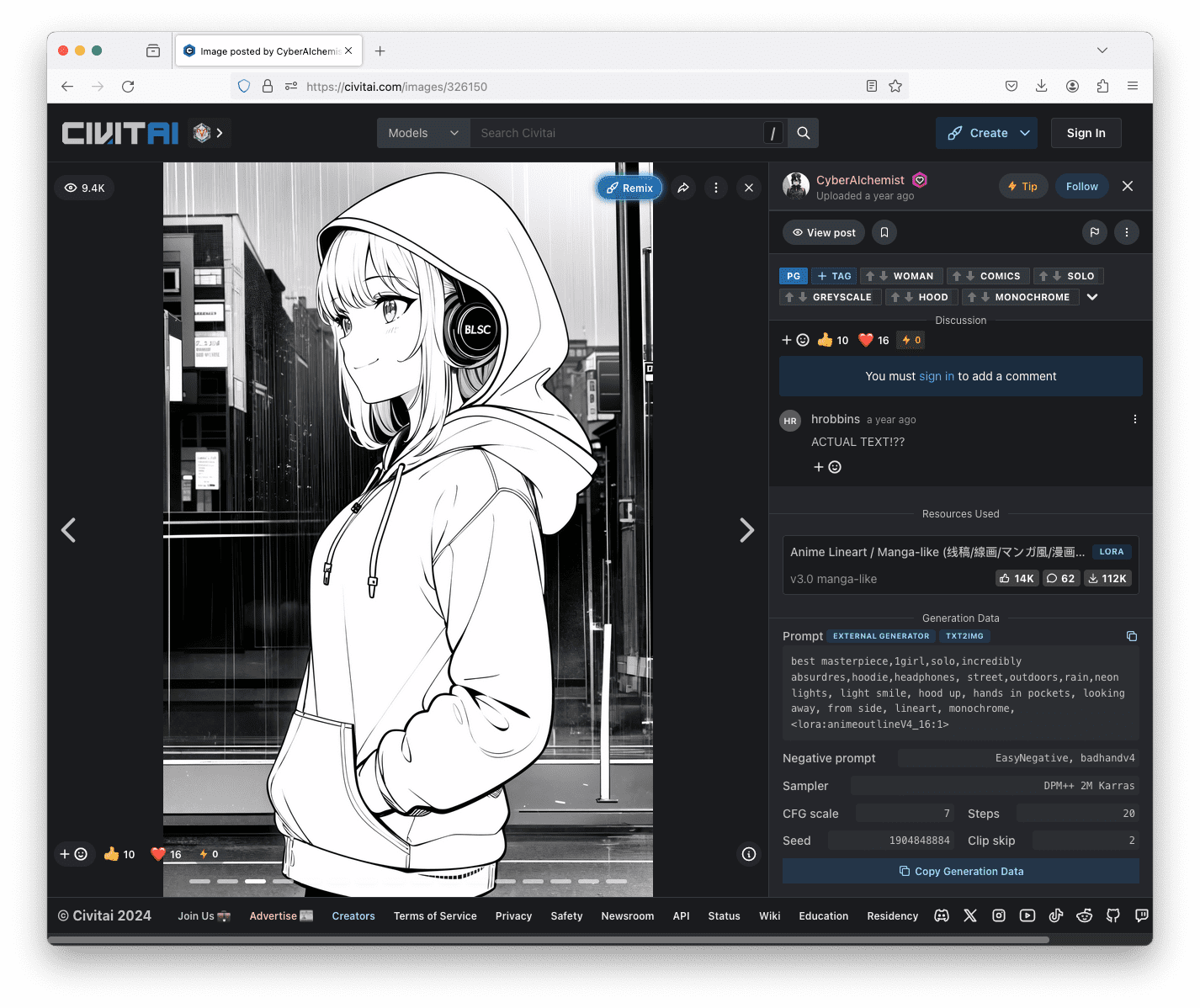
Testing a picture posted on Civitai can see the immediate and different parameters used to generate it on the proper half of the display screen.
As a ultimate comment, LoRA depends upon the mannequin you used. For instance, Secure Diffusion v1.5 and SD XL are incompatible in structure so that you want a LoRA that match the model of your base mannequin.
Additional Readings
Beneath are there papers launched the LoRA fine-tuning methods:
Abstract
On this put up, you realized what’s LoRA in Secure Diffusion and why it’s a light-weight enhancement. You additionally realized that utilizing LoRA in Secure Diffusion Internet UI is as simple as including an additional key phrase to the immediate There are lots of LoRA fashions developed by Secure Diffusion customers and put up on the Web so that you can obtain. You will discover one to simply change the generated end result with out a lot worrying on how one can describe the fashion you need it to vary.








 earbuds are up for pre-order, ChatGPT integration incoming")

")

")







/cdn.vox-cdn.com/uploads/chorus_asset/file/25661290/Screenshot_2024_10_06_at_10.48.36_AM.png "Trailers of the week: Nosferatu, The Franchise, and Squid Game 2")




{kind=link}