

Machine studying focuses on creating algorithms that allow computer systems to be taught from knowledge and enhance efficiency over time. It has revolutionized domains akin to picture recognition, pure language processing, and customized suggestions. This analysis subject leverages huge datasets and superior computational capabilities, pushing the boundaries of what’s attainable in synthetic intelligence and opening new frontiers in automation, decision-making, and predictive analytics.
One of many main challenges dealing with machine studying is the opacity surrounding how fashions make choices. Typically extremely correct, these fashions operate as ‘black containers,’ offering minimal perception into their inside logic. This lack of interpretability is especially regarding in delicate areas like healthcare, finance, and regulation, the place understanding the rationale behind choices is essential. Stakeholders in these sectors require clear fashions, as automated choices’ penalties can have important moral and sensible implications.
Current analysis contains common benchmarks like GSM8k, MATH, and MBPP for evaluating reasoning in massive language fashions (LLMs). These benchmarks embody datasets that check fashions on elementary mathematical reasoning, coding duties, and problem-solving abilities. Furthermore, latest research on overfitting have measured fashions’ skill to generalize utilizing modified variations of current datasets like ImageNet and CIFAR-10. These frameworks assess LLMs’ reasoning by evaluating mannequin efficiency on novel and recognized knowledge.
Researchers from Scale AI have launched GSM1k, a brand new benchmark created to measure overfitting and reasoning capabilities in LLMs. The researchers developed this benchmark by creating 1,250 elementary math issues that mirror the complexity and content material of current benchmarks like GSM8k. The benchmark goals to determine whether or not fashions depend on memorization or possess real reasoning capabilities by evaluating mannequin performances throughout related however distinct datasets.
The methodology behind GSM1k includes producing a brand new dataset of 1,250 elementary math issues. These have been designed to match the complexity of benchmarks like GSM8k, guaranteeing comparable problem ranges. The researchers employed human annotators to create points that required fundamental arithmetic and reviewed the issues by means of a number of high quality checks. They in contrast the outcomes of fashions throughout GSM1k and GSM8k to measure efficiency variations, emphasizing how fashions resolve issues slightly than memorizing solutions. This setup offers a transparent understanding of mannequin capabilities and identifies systematic overfitting.
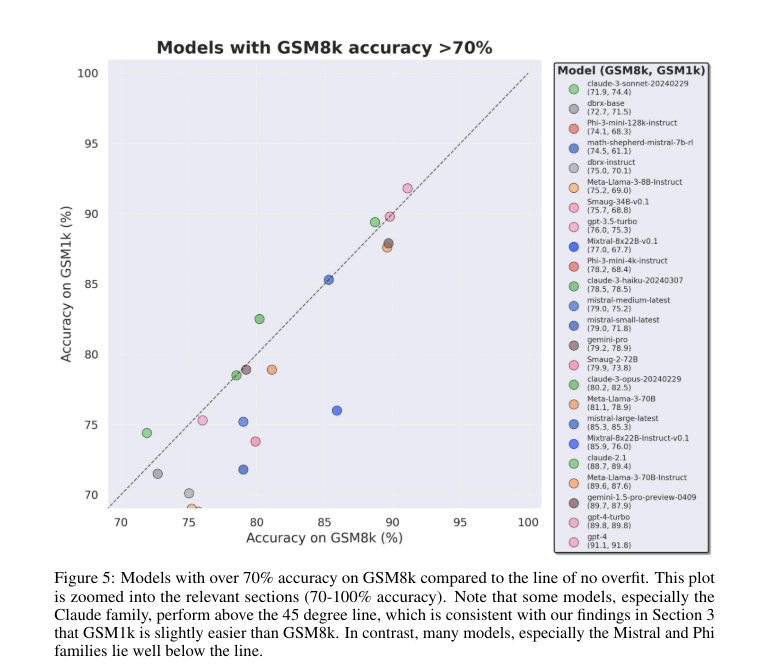
The analysis revealed important variations in mannequin efficiency between GSM8k and GSM1k, indicating systematic overfitting in sure fashions. As an illustration, Phi-3 confirmed a ten% drop in accuracy when transferring from GSM8k to GSM1k, demonstrating reliance on memorized knowledge. Nevertheless, different fashions like Gemini and Claude exhibited minimal variations, with an accuracy hole of underneath 5%. These findings counsel that some fashions have robust reasoning capabilities, whereas others depend on coaching knowledge memorization, evidenced by substantial efficiency gaps between the 2 datasets.
To conclude, the analysis offers a novel method to evaluating mannequin interpretability and efficiency by means of GSM1k, a benchmark designed to measure reasoning in machine studying fashions. By evaluating outcomes with the present GSM8k dataset, researchers uncovered various ranges of overfitting and reasoning throughout completely different fashions. The significance of this examine lies in its skill to tell apart between real reasoning and memorization in fashions, highlighting the necessity for improved interpretability strategies and guiding future developments in machine studying.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter. Be part of our Telegram Channel, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our e-newsletter..
Don’t Neglect to hitch our 41k+ ML SubReddit
![]()
Nikhil is an intern marketing consultant at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s all the time researching functions in fields like biomaterials and biomedical science. With a powerful background in Materials Science, he’s exploring new developments and creating alternatives to contribute.









")

")









")

{kind=link}