

Simply to offer you a fast refresher, the Pi 5 is a tiny laptop with a 4-core Cortex-A76 CPU, as much as 8GB of RAM, and a VideoCore VI GPU. It is principally a pocket-sized laptop.
Now, the true enjoyable begins. Our contenders for this experiment embody a various vary of LLMs, every with its personal strengths and limitations. We’ll be testing Phi-3.5B, Gemma2-2B, Qwen2.5-3B, Mistral-7B, and Llama 2-7B.
Let’s examine which of those language fashions can rise to the problem of working on a Raspberry Pi 5.
Testing Standards
To make sure a good and goal analysis of the LLMs, I used a standardized method with each mannequin.
I examined all of the fashions instantly in Ollama inside the terminal, and not using a GUI, to take away any overhead in efficiency and supply a bare-metal method to see how these fashions will carry out.
Activity: Every LLM had a process to generate a Docker Compose file for a WordPress set up with a MySQL database.
Metrics:
Inference time: The time elapsed from the immediate being issued to the completion of the Docker Compose file era. A shorter inference time signifies higher efficiency.Accuracy: The correctness and completeness of the generated Docker Compose file. We’ll assess whether or not the file precisely defines the required providers, networks, and volumes for a purposeful WordPress set up.Effectivity: The useful resource utilization of the LLM throughout the process. We’ll monitor CPU utilization, reminiscence consumption, and disk I/O to establish any efficiency bottlenecks.
Google’s Gemma 2 mannequin is obtainable in three sizes 2B, 9B, and 27B every with a brand new structure that goals to ship spectacular efficiency and effectivity.
As you may see within the video above, the efficiency of Google’s Gemma2 mannequin on the Raspberry Pi 5 was spectacular.
The inference time was quick, and the response high quality was wonderful whereas using solely 3 GB of RAM out of the out there 8 GB, leaving loads of headroom for different duties.
Given these outcomes, I’d price this setup a stable 5 out of 5 stars.
Qwen2.5 is the most recent era within the Qwen collection of enormous language fashions. It consists of numerous base fashions and instruction-tuned variations, out there in sizes from 0.5 to 72 billion parameters. Qwen2.5 brings a number of enhancements in comparison with its predecessor, Qwen2.
It’s my first time testing this mannequin and I used to be extremely impressed by it. The inference time was remarkably quick, and the responses had been correct and related.
It utilized 5.4 GB of RAM out of the out there 8 GB, leaving some headroom for different duties.
This implies you may simply use Qwen2.5 whereas juggling different private actions with none noticeable slowdowns.
Phi-3.5-mini is a compact, cutting-edge open mannequin derived from the Phi-3 household.
It’s skilled on the identical datasets, which embody artificial information and curated public web sites, emphasizing high-quality, reasoning-rich data.
With a context size of 128K tokens, this mannequin has been refined by a complete course of that mixes supervised fine-tuning, proximal coverage optimization, and direct choice optimization to reinforce its skill to comply with directions precisely and preserve sturdy security protocols.
In my check of Microsoft’s Phi 3.5 mannequin, the efficiency was considerably okayish.
Whereas the inference time wasn’t too shabby and the responses initially appeared good, the mannequin began to hallucinate and produce inaccurate outputs.
I needed to forcefully stop it after about 11 minutes, because it confirmed no indicators of stopping and would possible have continued indefinitely.
The mannequin utilized round 5 GB of RAM, which left some capability for different duties, however the hallucinations in the end detracted from the general expertise.
Mistral is a 7-billion-parameter mannequin launched underneath the Apache license, supplied in each instruction-following and textual content completion variants.
Based on the Mistral AI crew, Mistral 7B surpasses Llama2- 13B throughout all benchmarks and even outperforms Llama 1 34B in a number of areas.
It additionally delivers efficiency near CodeLlama 7B for coding duties, whereas nonetheless excelling typically English language duties.
I used to be skeptical about this mannequin because it was a 7b parameter mannequin however throughout my testing on Pi 5, it did handle to finish the given duties, though the inference time wasn’t tremendous speedy round 6 minutes.
It utilized solely 5 GB of RAM, which is spectacular given its measurement, and the responses had been right and aligned with my expectations.
Whereas I would not depend on this mannequin for each day use on the Pi, it is undoubtedly good to have as an possibility for extra complicated duties when wanted.
Llama 2, developed by Meta Platforms, Inc., is skilled on a dataset of two trillion tokens and natively helps a context size of 4,096 tokens.
The Llama 2 Chat fashions are particularly optimized for conversational use, fine-tuned with greater than 1 million human annotations to reinforce their chat capabilities.
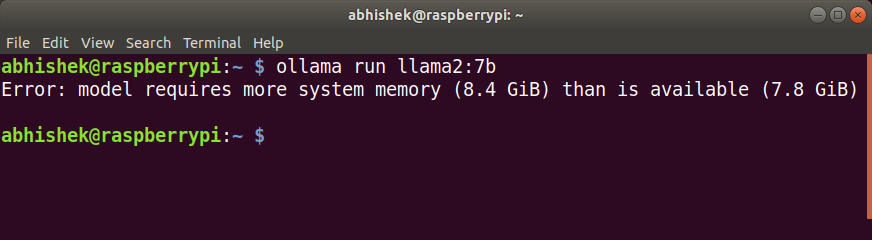
Effectively properly properly, as you may see above in my try to run the Llama 2 mannequin, I discovered that it merely didn’t work attributable to its increased RAM necessities.
Code Llama, based mostly on Llama 2, is a mannequin created to help with code era and dialogue.
It goals to streamline improvement workflows and simplify the coding studying course of.
Able to producing each code and explanatory pure language, Code Llama helps a variety of fashionable programming languages, comparable to Python, C++, Java, PHP, Typescript (Javascript), C#, Bash, and others.
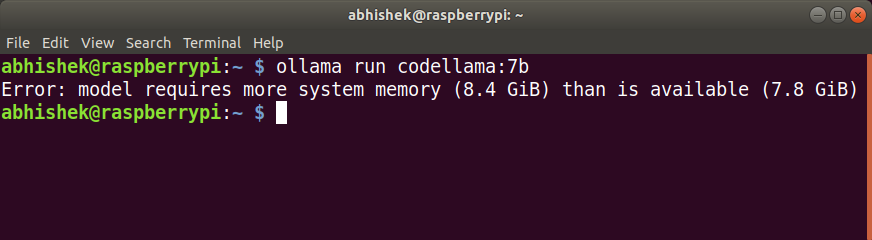
Much like llama2 mannequin, attributable to its increased RAM necessities, it did not run in any respect on my Raspberry Pi 5.
Nemotron-Mini-4B-Instruct is designed to generate responses for roleplaying, retrieval-augmented era (RAG), and performance calling.
It’s a small language mannequin (SLM) that has been refined for pace and on-device deployment utilizing distillation, pruning, and quantization methods.
Optimized particularly for roleplay, RAG-based QA, and performance calling in English, this instruct mannequin helps a context size of 4,096 tokens and is prepared for industrial functions.
Throughout my testing of Nemotron-Mini-4B-Instruct, I discovered the mannequin to be fairly environment friendly.
It managed to ship responses rapidly, with an inference time of underneath 2 minutes, whereas utilizing simply 4 GB of RAM.
This stage of efficiency makes it a viable possibility in your private co-pilot on Pi.
Orca Mini is a collection of fashions based mostly on Llama and Llama 2, skilled utilizing the Orca Type datasets as outlined within the paper “Orca: Progressive Studying from Complicated Clarification Traces of GPT-4.”
There are two variations: the unique Orca Mini, which is constructed on Llama and is available in 3, 7, and 13 billion parameter sizes, and model 3, based mostly on Llama 2, out there in 7, 13, and 70 billion parameter sizes.
Orca Mini utilized 4.5 GB of RAM out of the out there 8 GB, and the inference time was good.
Whereas I’m not fully positive concerning the accuracy of the responses, which is able to must be verified by testing the output file, I’d nonetheless suggest this mannequin for its effectivity and efficiency.
CodeGemma is a flexible set of light-weight fashions able to dealing with a spread of coding duties, together with fill-in-the-middle code completion, code era, pure language understanding, mathematical reasoning, and following directions.
My expertise with CodeGemma was fairly fascinating. As a substitute of responding to any of my queries, the mannequin amusingly started asking me questions, nearly as if it had a character of its personal.
I consider this habits may be attributable to its give attention to code completion, so I plan to check it in an IDE to see the way it performs in that context.
Regardless of the surprising interactions, it efficiently loaded up in Ollama and used solely 2.5 GB of RAM, which is spectacular for such a light-weight mannequin.
My Rankings
Please observe that every one the scores offered are subjective and based mostly on my private expertise testing these fashions.
They replicate how every mannequin carried out for me on the Raspberry Pi 5, however outcomes could differ relying on totally different setups and use circumstances.
I encourage you to take these scores with a grain of salt and experiment for your self to see what works finest in your wants.
LLM
Rankings
Gemma 2 (2b)
⭐⭐⭐⭐
Qwen 2.5 (3b)
⭐⭐⭐⭐⭐
Phi 3.5 (3.8b)
⭐⭐
Mistral (7b)
⭐⭐⭐
Llama 2 (7b)
–
Codellama (7b)
–
Nemotron-mini (4b)
⭐⭐⭐⭐
Orca-mini (3b)
⭐⭐⭐
Codegemma (2b)
⭐
Closing Ideas
Testing a variety of LLMs on the Raspberry Pi 5 has offered helpful insights into the sorts of fashions that may realistically run on this compact machine.
Usually, fashions underneath 7 billion parameters are well-suited for the Pi, providing a superb steadiness between efficiency and useful resource utilization.
Nonetheless, there are exceptions like Mistral 7B, which, regardless of being a bigger mannequin, ran superb albeit a bit gradual.
Fashions within the 2B, 3B, and 4B vary, alternatively, carried out exceptionally properly, demonstrating the Pi’s functionality to deal with subtle AI duties.
As we proceed to advance within the discipline of AI, I consider we’ll see extra fashions being optimized for smaller units just like the Raspberry Pi.
What do you assume? Are there any fashions you’re attempting out in your Pi? Do tell us!










")












{kind=link}