

From the immediate to the image, Secure Diffusion is a pipeline with many elements and parameters. All these elements working collectively creates the output. If a part behave in another way, the output will change. Subsequently, a foul setting can simply wreck your image. On this publish, you will notice:
How the completely different elements of the Secure Diffusion pipeline impacts your output
The way to discover the very best configuration that can assist you generate a top quality image
Let’s get began.
The way to Use Secure Diffusion Successfully.Picture by Kam Idris. Some rights reserved.
Overview
This publish is in three components; they’re:
Significance of a Mannequin
Choosing a Sampler and Scheduler
Dimension and the CFG Scale
Significance of a Mannequin
If there may be one part within the pipeline that has probably the most influence, it have to be the mannequin. Within the Net UI, it’s known as the “checkpoint”, named after how we saved the mannequin once we educated a deep studying mannequin.
The Net UI helps a number of Secure Diffusion mannequin architectures. The commonest structure these days is the model 1.5 (SD 1.5). Certainly, all model 1.x share the same structure (every mannequin has 860M parameters) however are educated or fine-tuned below completely different methods.
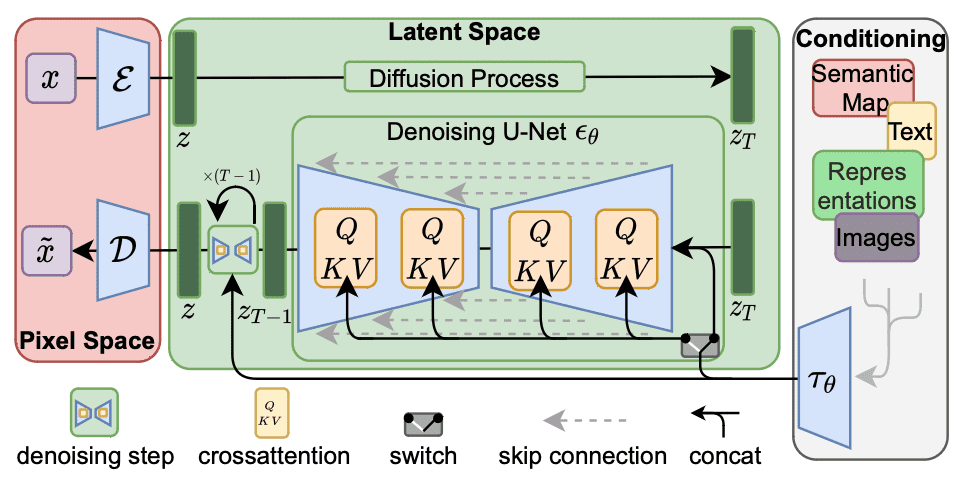
Structure of Secure Diffusion 1.x. Determine from Rombach et al (2022)
There may be additionally Secure Diffusion 2.0 (SD 2.0), and its up to date model 2.1. This isn’t a “revision” from model 1.5, however a mannequin educated from scratch. It makes use of a special textual content encoder (OpenCLIP as a substitute of CLIP); subsequently, they’d perceive key phrases in another way. One noticeable distinction is that OpenCLIP is aware of fewer names of celebrities and artists. Therefore, the immediate from Secure Diffusion 1.5 could also be out of date in 2.1. As a result of the encoder is completely different, SD2.x and SD1.x are incompatible, whereas they share the same structure.
Subsequent comes the Secure Diffusion XL (SDXL). Whereas model 1.5 has a local decision of 512×512 and model 2.0 elevated it to 768×768, SDXL is at 1024×1024. You aren’t recommended to make use of a vastly completely different measurement than their native decision. SDXL is a special structure, with a a lot bigger 6.6B parameters pipeline. Most notably, the fashions have two components: the Base mannequin and the Refiner mannequin. They arrive in pairs, however you may swap out considered one of them for a suitable counterpart, or skip the refiner if you want. The textual content encoder used combines CLIP and OpenCLIP. Therefore, it ought to perceive your immediate higher than any older structure. Working SDXL is slower and requires way more reminiscence, however often in higher high quality.
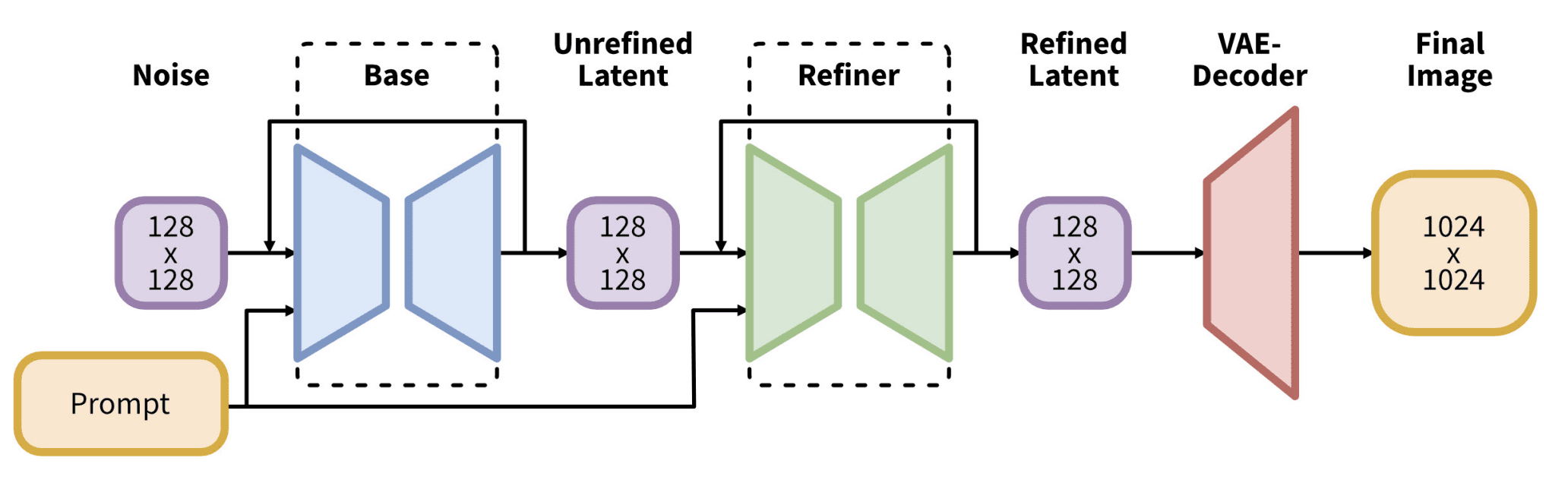
Structure of SDXL. Determine from Podell et al (2023)
What issues to you is that it’s best to classify your fashions into three incompatible households: SD1.5, SD2.x, and SDXL. They behave in another way together with your immediate. Additionally, you will discover that SD1.5 and SD2.x would wish a damaging immediate for image, however it’s much less vital in SDXL. If you happen to’re utilizing SD2.x fashions, additionally, you will discover that you may choose your refiner within the Net UI.

Photographs generated with the immediate, ‘A quick meals restaurant in a desert with identify “Sandy Burger”’, utilizing SD 1.5 with completely different random seed. Be aware that none of them spelled the identify appropriately.

Photographs generated with the immediate, ‘A quick meals restaurant in a desert with identify “Sandy Burger”’, utilizing SD 2.0 with completely different random seed. Be aware that not all of them spelled the identify appropriately.

Photographs generated with the immediate, ‘A quick meals restaurant in a desert with identify “Sandy Burger”’, utilizing SDXL with completely different random seed. Be aware that each one of them spelled the identify appropriately.
One attribute of Secure Diffusion is that the unique fashions are much less succesful however adaptable. Subsequently, numerous third-party fine-tuned fashions are produced. Most important are the fashions specializing in sure kinds, comparable to Japanese anime, western cartoons, Pixar-style 2.5D graphics, or photorealistic photos.
You will discover fashions on Civitai.com or Hugging Face Hub. Search with key phrases comparable to “photorealistic” or “2D” and sorting by score would often assist.
Choosing a Sampler and Scheduler
Picture diffusion is to start out with noise and replaces the noise strategically with pixels till the ultimate image is produced. It’s later discovered that this course of might be represented as a stochastic differential equation. Fixing the equation numerically is feasible, and there are completely different algorithms of various accuracy.
Essentially the most generally used sampler is Euler. It’s conventional however nonetheless helpful. Then, there’s a household of DPM samplers. Some new samplers, comparable to UniPC and LCM, have been launched not too long ago. Every sampler is an algorithm. It’s to run for a number of steps, and completely different parameters are utilized in every step. The parameters are set utilizing a scheduler, comparable to Karras or exponential. Some samplers have another “ancestral” mode, which provides randomness to every step. That is helpful if you would like extra artistic output. These samplers often bear a suffix “a” of their identify, comparable to “Euler a” as a substitute of “Euler”. The non-ancestral samplers converge, i.e., they are going to stop altering the output after sure steps. Ancestral samplers would give a special output for those who enhance the step measurement.

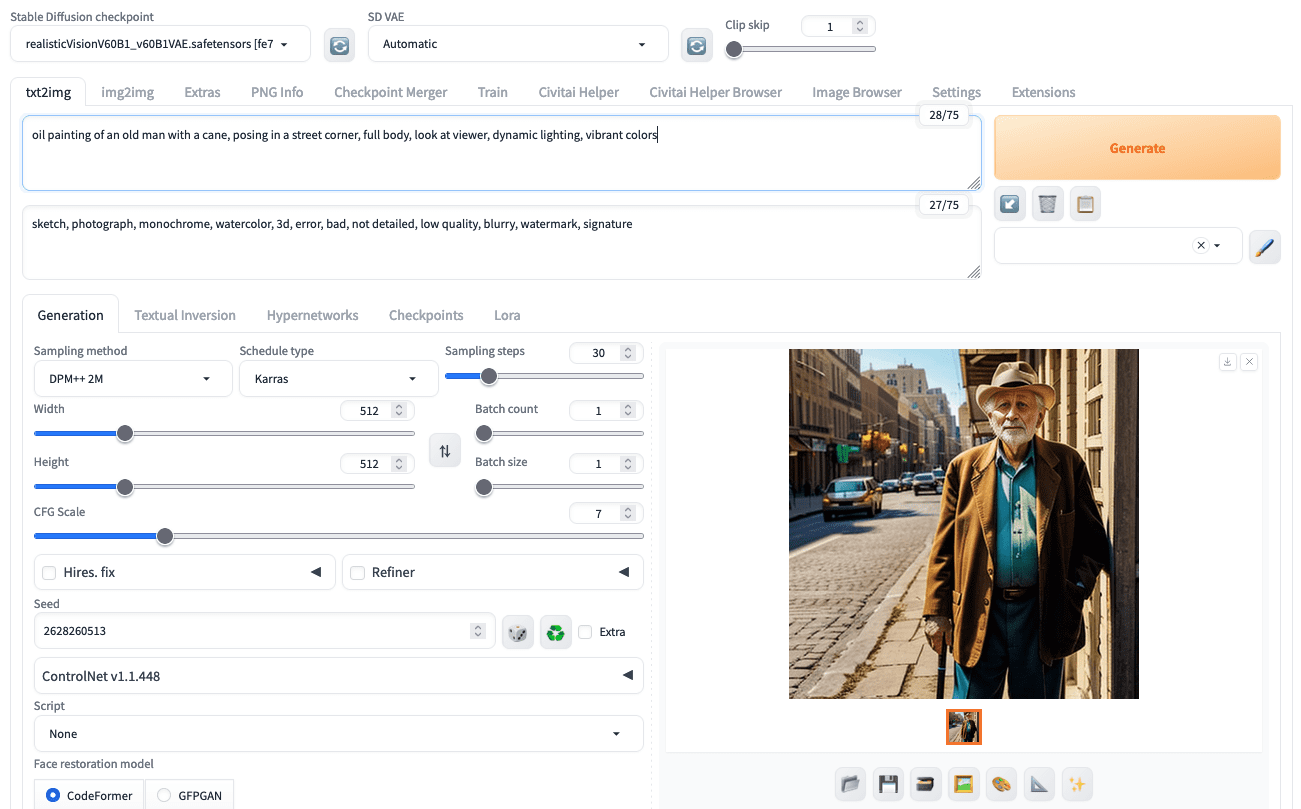
Choosing sampler, scheduler, steps, and different parameters within the Secure Diffusion Net UI
As a person, you may assume Karras is the scheduler for all instances. Nonetheless, the scheduler and step measurement would wish some experimentation. Both Euler or DPM++2M must be chosen as a result of they steadiness high quality and velocity greatest. You can begin with a step measurement of round 20 to 30; the extra steps you select, the higher the output high quality when it comes to particulars and accuracy, however proportionally slower.
Dimension and CFG Scale
Recall that the picture diffusion course of begins from a loud image, progressively inserting pixels conditioned by the immediate. How a lot the conditioning can influence the diffusion course of is managed by the parameter CFG scale (classifier-free steerage scale).
Sadly, the optimum worth of CFG scale is dependent upon the mannequin. Some fashions work greatest with a CFG scale of 1 to 2, whereas others are optimized for 7 to 9. The default worth is 7.5 within the Net UI. However as a basic rule, the upper the CFG scale, the stronger the output picture conforms to your immediate.
In case your CFG scale is just too low, the output picture might not be what you anticipated. Nonetheless, there may be one more reason you don’t get what you anticipated: The output measurement. For instance, for those who immediate for an image of a person standing, chances are you’ll get a headshot of a half-body shot as a substitute except you set the picture measurement to a peak considerably larger than the width. The diffusion course of units the image composition within the early steps. It’s simpler to plan a standing man on a taller canvas.
Producing a half-body shot if supplied a sq. canvas.

Producing a full physique shot with the identical immediate, identical seed, and solely the canvas measurement is modified.
Equally, for those who give an excessive amount of element to one thing that occupies a small a part of the picture, these particulars can be ignored as a result of there should not sufficient pixels to render these particulars. That’s the reason SDXL, for instance, is mostly higher than SD 1.5 because you often use a bigger pixel measurement.
As a ultimate comment, producing photos utilizing picture diffusion fashions includes randomness. All the time begin with a batch of a number of photos to verify the unhealthy output isn’t merely because of the random seed.
Additional Readings
This part offers extra assets on the subject if you wish to go deeper.
Abstract
On this publish, you realized about some delicate particulars that impacts the picture era in Secure Diffusion. Particularly, you realized:
The distinction between completely different variations of Secure Diffusion
How the scheduler and sampler impacts the picture diffusion course of
How the canvas measurement could have an effect on the output






")



")

")







")




{kind=link}