

What’s the optimum framework and configuration for internet hosting massive language fashions (LLMs) for text-generating generative AI purposes? Regardless of the abundance of choices for serving LLMs, it is a arduous query to reply because of the dimension of the fashions, various mannequin architectures, efficiency necessities of purposes, and extra. The Amazon SageMaker Giant Mannequin Inference (LMI) container makes it simple to serve LLMs by bringing collectively a bunch of various frameworks and strategies that optimize the deployment of LLMs. The LMI container has a strong serving stack referred to as DJL serving that’s agnostic to the underlying LLM. It supplies system-level configuration parameters that may be tuned for extracting the perfect efficiency of the internet hosting infrastructure for a given LLM. It additionally has assist for latest optimizations like steady batching, also referred to as iterative batching or rolling batching, which supplies important enhancements in throughput.
In an earlier submit, we confirmed how you should utilize the LMI container to deploy the Falcon household of fashions on SageMaker. On this submit, we reveal the best way to enhance the throughput and latency of serving Falcon-40B with strategies like steady batching. We additionally present an intuitive understanding of configuration parameters offered by the SageMaker LMI container that may enable you discover the perfect configuration in your real-world software.
Fundamentals of text-generative inference for LLMs
Let’s first take a look at a number of fundamentals on the best way to carry out inference for LLMs for textual content era.
Ahead go, activations, and the KV cache
Given an enter sequence of tokens, they’re run in a ahead go throughout all of the layers of the LLM (like Falcon) to generate the subsequent token. A ahead go refers back to the strategy of enter information being handed by way of a neural community to provide an output. Within the case of textual content era, the ahead go includes feeding an preliminary seed or context into the language mannequin and producing the subsequent character or token within the sequence. To generate a sequence of textual content, the method is commonly carried out iteratively, that means it’s repeated for every step or place within the output sequence. At every iteration, the mannequin generates the subsequent character or token, which turns into a part of the generated textual content, and this course of continues till the specified size of textual content is generated.
Textual content era with language fashions like Falcon or GPT are autoregressive. Because of this the mannequin generates one token at a time whereas conditioning on the beforehand generated tokens. In different phrases, at every iteration, the mannequin takes the beforehand generated textual content as enter and predicts the subsequent token primarily based on that context. As talked about in vLLM: Simple, Quick, and Low cost LLM Serving with PagedAttention, on this autoregressive decoding course of, all of the enter tokens to the LLM produce their consideration key and worth tensors, and these tensors are saved in GPU reminiscence to generate subsequent tokens. These cached key and worth tensors are sometimes called the KV cache.
Prefill and decode phases
In an autoregressive decoding course of, just like the one utilized in textual content era with language fashions corresponding to Falcon, there are usually two major phases: the prefill part and the decode part. These phases are essential for producing coherent and contextually related textual content.
The prefill part consists of the next:
Preliminary context – The prefill part begins with an preliminary context or seed textual content offered by the person. This preliminary context could be a sentence, a phrase, and even only a single phrase. It units the start line for textual content era and supplies context for what comes subsequent.
Mannequin conditioning – The offered context is used to situation the language mannequin. The mannequin takes this context as enter and generates the subsequent token (phrase or character) within the sequence primarily based on its understanding of the context.
Token era – The mannequin generates one token at a time, predicting what ought to come subsequent within the textual content. This token is appended to the context, successfully extending it.
Iterative course of – The method of producing tokens is repeated iteratively. At every step, the mannequin generates a token whereas contemplating the up to date context, which now consists of the tokens generated in earlier steps.
The prefill part continues till a predetermined stopping situation is met. This situation could be a most size for the generated textual content, a particular token that indicators the top of the textual content, or another standards set by the person or the applying.
The decode part consists of the next:
Completion – After the prefill part, you might have {a partially} generated textual content that could be incomplete or minimize off in some unspecified time in the future. The decode part is accountable for finishing the textual content to make it coherent and grammatically appropriate.
Continuation from the final token – Within the decode part, the mannequin begins from the final token generated through the prefill part. It makes use of this token because the preliminary context and generates the subsequent token to proceed the textual content.
Iterative completion – Like within the prefill part, the method of producing tokens is once more iterative. The mannequin generates one token at a time, conditioning on the previous tokens within the sequence.
Stopping situation – The decode part additionally has a stopping situation, which is likely to be the identical as within the prefill part, corresponding to reaching a most size or encountering an end-of-text token. When this situation is met, the era course of stops.
The mix of the prefill and decode phases permits autoregressive fashions to generate textual content that builds on an preliminary context and produces coherent, contextually related, and contextually constant sequences of textual content.
Check with A Distributed Serving System for Transformer-Based mostly Generative Fashions for an in depth clarification of the method.
Optimizing throughput utilizing dynamic batching
Thus far, we’ve solely talked a few single enter. In follow, we count on to take care of a number of requests coming in randomly from the applying purchasers for inference concurrently or in a staggered trend. Within the conventional method, fundamental batching can be utilized to extend the throughput and the utilization of the computing assets of the GPU. Batching is successfully combining the numerical representations of a couple of request in a batch and performing parallel runs of the autoregressive ahead passes. This clever batching is finished on the serving facet. SageMaker LMI’s DJLServing server will be configured to batch collectively a number of requests to course of them in parallel by setting the next parameters in serving.properties:
max_batch_delay = 100 – The utmost delay for batch aggregation in milliseconds. The default worth is 100 milliseconds.
batch_size = 32 – The dynamic batch dimension. The default is 1.
This principally exhibits that DJLServing will queue up requests for 100 milliseconds at a time or if the variety of requests which might be queued up are as much as the batch_size specified, the batch shall be scheduled to run to the backend for inference. This is named dynamic batching. It’s dynamic as a result of the batch dimension might change throughout batches relying on what number of requests have been added in that point length. Nevertheless, as a result of requests may need totally different traits, (for instance, some requests is likely to be of form 20 tokens of enter and 500 tokens of output, whereas others is likely to be reversed, with 500 tokens of enter however solely 20 for output), some requests may full processing quicker than others in the identical batch. This might end in underutilization of the GPU whereas ready for all in-flight requests within the batch to finish its decode stage, even when there are extra requests ready to be processed within the queue. The next diagram illustrates this course of.
Dynamic Batching Visible – discover the idle home windows on the finish of Request 2 and three
Optimizing throughput utilizing steady batching
With steady batching, also referred to as iterative or rolling batching, we benefit from the variations between the prefill and decode levels. To activate steady batching, DJServing supplies the next extra configurations as per serving.properties:
engine=MPI – We encourage you to make use of the MPI engine for steady batching.
choice.rolling_batch=auto or lmi-dist – We advocate utilizing auto as a result of it’ll mechanically choose essentially the most acceptable rolling batch algorithm together with different optimizations sooner or later.
choice.max_rolling_batch_size=32 – This limits the variety of concurrent requests. The default is 32.
With steady batching, the serving stack (DJLServing) doesn’t look ahead to all in-flight requests in a batch to finish its decode stage. Reasonably, at logical breaks (on the finish of 1 iteration within the decode stage), it pulls in extra requests which might be ready within the queue whereas the present batch remains to be processing (therefore the identify rolling batch). It does this test for pending requests on the finish of every iteration of the decode stage. Keep in mind, for every request, we have to run the prefill stage adopted by the sequential decode stage. As a result of we are able to course of all of the tokens from the preliminary immediate of a request in parallel for its prefill stage, anytime a brand new request is pulled in, we quickly pause the decode stage of in-flight requests of the batch—we quickly save its KV cache and activations in reminiscence and run the prefill stage of the brand new requests.
The dimensions of this cache will be configured with the next choice:
When the prefill is full, we mix the brand new requests and the outdated paused requests in a brand new rolling batch, which may proceed with their decode stage in parallel. Notice that the outdated paused requests can proceed their decode stage the place they left off and the brand new requests will begin from their first new token.
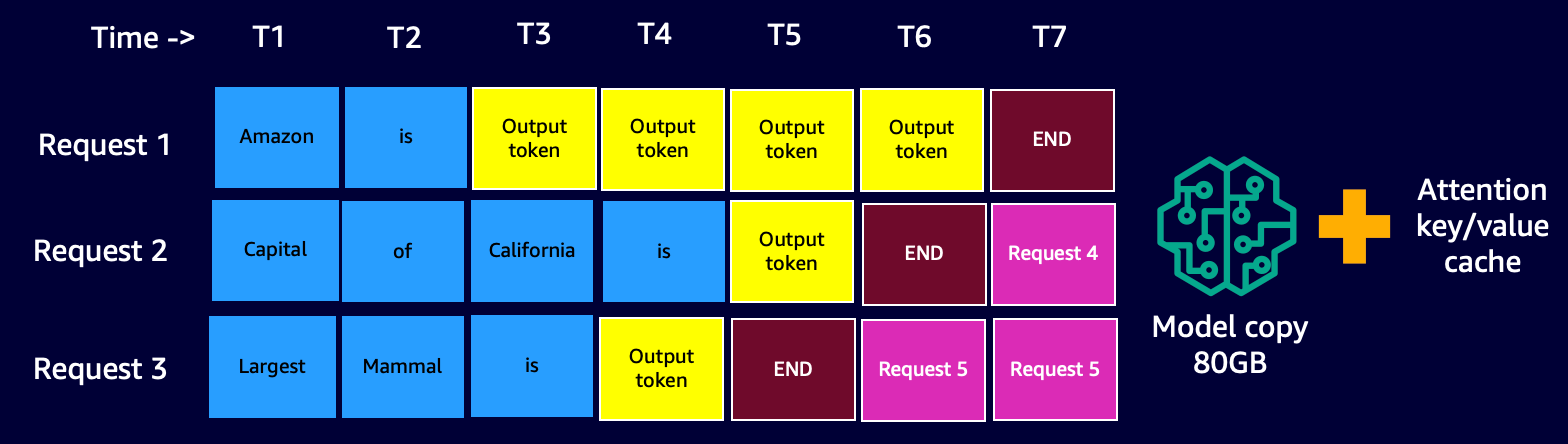
Steady or Iterative Batching Visible – discover that the idle occasions are changed with observe on requests
You may need already realized that steady batching is an virtually comparable strategy with which we naturally parallelize duties in our day by day lives. Now we have messages, emails, telephone notifications (doubtlessly new requests) coming in at random occasions (analogous to a number of requests coming in a random staggered trend for GPUs). That is all occurring whereas we go about finishing our in-flight duties—composing emails, coding, taking part in conferences (analogous to the at present processing duties within the GPUs). At logical breaks, we pause our in-flight duties and test our notifications to resolve if there may be some motion required on our half, and if there may be, we add it to our in-flight duties (real-life rolling batch), or put it on a to-do record (the queue).
Placing all of it collectively: How to consider reminiscence utilization of GPUs
It’s really helpful to load check your mannequin to see which configuration is essentially the most cost-effective for your online business use case. To construct an understanding, let’s visualize the reminiscence footprint of the GPUs because the mannequin is loaded and as successive requests are processed in a rolling batch. For this submit, let’s assume we’re loading the Falcon-40B mannequin onto one of many G5 occasion sorts occasion which might be put in with NVIDIA A10G GPUs, every with 24 GB of reminiscence. Notice {that a} comparable understanding is relevant for the p3, p4, and p5 occasion sorts, which include the V100, A100, and H100 GPU collection.
The next is the overview of getting an approximate worth of complete reminiscence required to serve Falcon-40B:
Mannequin dimension = Variety of mannequin parameters (40 billion for Falcon-40B) x 4 bytes per parameter (for FP32) = 160 GB
Approximate complete reminiscence required to load Falcon-40B for inference = Mannequin dimension (=160 GB) + KV Cache (Consideration Cache) (=*20 GB) + Further reminiscence overhead by ML Frameworks (roughly 2 GB)

Reminiscence Visible – Understanding the reminiscence footprint of a loaded Falcon-40B mannequin
For Falcon-40B, if we compress the mannequin by quantizing the mannequin to the bfloat16 (2 bytes) information sort, the mannequin dimension turns into roughly 80 GB. As you may see, that is nonetheless bigger than the reminiscence supported by one accelerator system, so we have to undertake a mannequin partitioning (sharding) approach with a particular tensor parallelism (TP) strategy and shard the mannequin throughout a number of accelerator gadgets. Let’s assume that we’ve got chosen g5.24xlarge, which has 4 A10G GPU gadgets. If we configure DJLServing (serving.properties) with the next, we are able to count on that the 80 GB of mannequin weights shall be divided equally throughout all 4 GPUs:
With tensor_parallel_degree set to 4, about 20 GB of the 24 GB GPU reminiscence (roughly 84%) is already utilized even earlier than a single request has been processed. The remaining 16% of the GPU shall be used for the KV cache for the incoming requests. It’s attainable that for your online business situation and its latency and throughput necessities, 2–3 GB of the remaining reminiscence is greater than sufficient. If not, you may enhance the occasion dimension to g5.48xlarge, which has 8 GPUs and makes use of tensor_parallel_degree set to eight. In such a case, solely roughly 10 GB of the obtainable 24 GB reminiscence of every GPU is utilized for mannequin weights and we’ve got about 60% of the remaining GPU for the activations and KV cache. Intuitively, we are able to see that this configuration might enable us to have a better throughput. Moreover, as a result of we’ve got a bigger buffer now, we are able to enhance the max_rolling_batch_prefill_tokens and max_rolling_batch_size parameters to additional optimize the throughput. Collectively, these two parameters will management the preallocations of the activation prefills and KV cache for the mannequin. A bigger quantity for these two parameters will co-relate to a bigger throughput, assuming you might have sufficient buffer for the KV cache within the GPU reminiscence.
Steady batching with PagedAttention
PagedAttention is a brand new optimization algorithm developed by UC Berkeley that improves the continual batching course of by permitting the eye cache (KV cache) to be non-contiguous by allocating reminiscence in fixed-size pages or blocks. That is impressed by digital reminiscence and paging ideas utilized by working methods.
As per the vLLM paper, the eye cache of every sequence of tokens is partitioned into blocks and mapped to bodily blocks by way of a block desk. Through the computation of consideration, a PagedAttention kernel can use the block desk to effectively fetch the blocks from bodily reminiscence. This ends in a major discount of reminiscence waste and permits for bigger batch dimension, elevated GPU utilization, and better throughput.
Efficiency comparability
To make sure efficient load testing of your deployment configuration, it’s really helpful to start by contemplating the enterprise situation and clearly defining the traits of the enter and output for the LLM-based software. For example, if you’re engaged on a name heart summarization use case, the enter may encompass bigger textual content, corresponding to a 500-token chat transcript between a customer support agent and a buyer, however the output is likely to be comparatively smaller, round 100 tokens, representing a abstract of the transcript. Then again, in the event you’re engaged on a code era situation, the enter could possibly be as quick as 15 tokens, like “write an environment friendly implementation in Python for describing all EC2 assets, together with pagination,” however the output could possibly be a lot bigger, reaching 500 tokens. It’s additionally vital to think about whether or not attaining decrease latency or maximizing throughput is the highest precedence in your particular situation.
After gaining a complete understanding of the enterprise situation, you may analyze and decide the optimum configuration in your internet hosting surroundings. On this context, the internet hosting surroundings encompasses numerous key parts, together with the occasion sort and different configuration parameters corresponding to tensor_parallel_degree, max_rolling_batch_size, max_rolling_batch_prefill_tokens, and extra. Our goal is to determine the best setup to assist our response time, throughput, and mannequin output high quality necessities.
In our evaluation, we benchmarked the efficiency for example the advantages of steady batching over conventional dynamic batching. We used the configurations detailed within the following desk in serving.properties for dynamic batching and iterative batching, utilizing an LMI container on SageMaker.
Dynamic Batching
Steady Batching
Steady Batching with PagedAttention
engine=Python
choice.model_id=tiiuae/falcon-40b
choice.tensor_parallel_degree=8
choice.dtype=fp16
batch_size=4
max_batch_delay=100
choice.trust_remote_code = true
engine = MPI
choice.model_id = {{s3_url}}
choice.trust_remote_code = true
choice.tensor_parallel_degree = 8
choice.max_rolling_batch_size = 32
choice.rolling_batch = auto
choice.dtype = fp16
choice.max_rolling_batch_prefill_tokens = 1024
choice.paged_attention = False
engine = MPI
choice.model_id = {{s3_url}}
choice.trust_remote_code = true
choice.tensor_parallel_degree = 8
choice.max_rolling_batch_size = 32
choice.rolling_batch = auto
choice.dtype = fp16
choice.max_rolling_batch_prefill_tokens = 1024
choice.paged_attention = True
The 2 configurations have been benchmarked for Falcon-40B with the FP16 information sort deployed on ml.g5.48xlarge in a few totally different situations that signify real-world purposes:
A small variety of enter tokens with a lot of tokens being generated – On this situation, variety of enter tokens was fastened at 32 and 128 new tokens have been generated
Batching Technique
Throughput (tokens/sec)
Latency p90 (secs)
Dynamic Batching
5.53
58.34
Steady Batching
56.04
4.74
Steady Batching with PagedAttention
59.18
4.76
A big enter with a small variety of tokens being generated – Right here, we repair the variety of enter tokens at 256 and immediate the LLM to summarize the enter to 32 tokens
Batching Technique
Throughput (tokens/sec)
Latency p90 (secs)
Dynamic Batching
19.96
59.31
Steady Batching
46.69
3.88
Steady Batching with PagedAttention
44.75
2.67
We will see that steady batching with PagedAttention supplies a throughput enchancment of 10 occasions larger in situation 1 and a couple of.3 occasions in situation 2 in comparison with utilizing dynamic batching on SageMaker whereas utilizing the LMI container.
Conclusion
On this submit, we checked out how LLMs use reminiscence and defined how steady batching improves the throughput utilizing an LMI container on SageMaker. We demonstrated the advantages of steady batching for Falcon-40B utilizing an LMI container on SageMaker by exhibiting benchmark outcomes. You will discover the code on the GitHub repo.
Concerning the Authors
 Abhi Shivaditya is a Senior Options Architect at AWS, working with strategic world enterprise organizations to facilitate the adoption of AWS providers in areas corresponding to Synthetic Intelligence, distributed computing, networking, and storage. His experience lies in Deep Studying within the domains of Pure Language Processing (NLP) and Pc Imaginative and prescient. Abhi assists clients in deploying high-performance machine studying fashions effectively inside the AWS ecosystem.
Abhi Shivaditya is a Senior Options Architect at AWS, working with strategic world enterprise organizations to facilitate the adoption of AWS providers in areas corresponding to Synthetic Intelligence, distributed computing, networking, and storage. His experience lies in Deep Studying within the domains of Pure Language Processing (NLP) and Pc Imaginative and prescient. Abhi assists clients in deploying high-performance machine studying fashions effectively inside the AWS ecosystem.
 Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from massive enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Pc Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.
Dhawal Patel is a Principal Machine Studying Architect at AWS. He has labored with organizations starting from massive enterprises to mid-sized startups on issues associated to distributed computing, and Synthetic Intelligence. He focuses on Deep studying together with NLP and Pc Imaginative and prescient domains. He helps clients obtain excessive efficiency mannequin inference on SageMaker.
 Pinak Panigrahi works with clients to construct machine studying pushed options to unravel strategic enterprise issues on AWS. When not occupied with machine studying, he will be discovered taking a hike, studying a e book or watching sports activities.
Pinak Panigrahi works with clients to construct machine studying pushed options to unravel strategic enterprise issues on AWS. When not occupied with machine studying, he will be discovered taking a hike, studying a e book or watching sports activities.
 Abhi Sodhani holds the place of Senior AI/ML Options Architect at AWS, the place he makes a speciality of providing technical experience and steerage on Generative AI and ML options to clients. His main focus is to help Digital Native Companies in realizing the total potential of Generative AI and ML applied sciences, enabling them to attain their enterprise targets successfully. Past his skilled endeavors, Abhi reveals a powerful ardour for mental pursuits corresponding to studying, in addition to partaking in actions that promote bodily and psychological well-being, corresponding to yoga, meditation.
Abhi Sodhani holds the place of Senior AI/ML Options Architect at AWS, the place he makes a speciality of providing technical experience and steerage on Generative AI and ML options to clients. His main focus is to help Digital Native Companies in realizing the total potential of Generative AI and ML applied sciences, enabling them to attain their enterprise targets successfully. Past his skilled endeavors, Abhi reveals a powerful ardour for mental pursuits corresponding to studying, in addition to partaking in actions that promote bodily and psychological well-being, corresponding to yoga, meditation.
 Qing Lan is a Software program Growth Engineer in AWS. He has been engaged on a number of difficult merchandise in Amazon, together with excessive efficiency ML inference options and excessive efficiency logging system. Qing’s staff efficiently launched the primary Billion-parameter mannequin in Amazon Promoting with very low latency required. Qing has in-depth data on the infrastructure optimization and Deep Studying acceleration.
Qing Lan is a Software program Growth Engineer in AWS. He has been engaged on a number of difficult merchandise in Amazon, together with excessive efficiency ML inference options and excessive efficiency logging system. Qing’s staff efficiently launched the primary Billion-parameter mannequin in Amazon Promoting with very low latency required. Qing has in-depth data on the infrastructure optimization and Deep Studying acceleration.










")

")







")




{kind=link}