

Giant language mannequin (LLM) brokers are packages that reach the capabilities of standalone LLMs with 1) entry to exterior instruments (APIs, capabilities, webhooks, plugins, and so forth), and a pair of) the flexibility to plan and execute duties in a self-directed style. Typically, LLMs must work together with different software program, databases, or APIs to perform complicated duties. For instance, an administrative chatbot that schedules conferences would require entry to staff’ calendars and e-mail. With entry to instruments, LLM brokers can change into extra highly effective—at the price of further complexity.
On this publish, we introduce LLM brokers and display the way to construct and deploy an e-commerce LLM agent utilizing Amazon SageMaker JumpStart and AWS Lambda. The agent will use instruments to supply new capabilities, resembling answering questions on returns (“Is my return rtn001 processed?”) and offering updates about orders (“May you inform me if order 123456 has shipped?”). These new capabilities require LLMs to fetch knowledge from a number of knowledge sources (orders, returns) and carry out retrieval augmented technology (RAG).
To energy the LLM agent, we use a Flan-UL2 mannequin deployed as a SageMaker endpoint and use knowledge retrieval instruments constructed with AWS Lambda. The agent can subsequently be built-in with Amazon Lex and used as a chatbot inside web sites or AWS Join. We conclude the publish with objects to contemplate earlier than deploying LLM brokers to manufacturing. For a completely managed expertise for constructing LLM brokers, AWS additionally supplies the brokers for Amazon Bedrock function (in preview).
A short overview of LLM agent architectures
LLM brokers are packages that use LLMs to determine when and the way to use instruments as obligatory to finish complicated duties. With instruments and activity planning talents, LLM brokers can work together with exterior techniques and overcome conventional limitations of LLMs, resembling data cutoffs, hallucinations, and imprecise calculations. Instruments can take quite a lot of types, resembling API calls, Python capabilities, or webhook-based plugins. For instance, an LLM can use a “retrieval plugin” to fetch related context and carry out RAG.
So what does it imply for an LLM to choose instruments and plan duties? There are quite a few approaches (resembling ReAct, MRKL, Toolformer, HuggingGPT, and Transformer Brokers) to utilizing LLMs with instruments, and developments are taking place quickly. However one easy manner is to immediate an LLM with a listing of instruments and ask it to find out 1) if a device is required to fulfill the consumer question, and if that’s the case, 2) choose the suitable device. Such a immediate sometimes appears to be like like the next instance and should embody few-shot examples to enhance the LLM’s reliability in selecting the correct device.
Extra complicated approaches contain utilizing a specialised LLM that may immediately decode “API calls” or “device use,” resembling GorillaLLM. Such finetuned LLMs are skilled on API specification datasets to acknowledge and predict API calls based mostly on instruction. Typically, these LLMs require some metadata about obtainable instruments (descriptions, yaml, or JSON schema for his or her enter parameters) with a view to output device invocations. This strategy is taken by brokers for Amazon Bedrock and OpenAI operate calls. Word that LLMs usually must be sufficiently giant and complicated with a view to present device choice skill.
Assuming activity planning and power choice mechanisms are chosen, a typical LLM agent program works within the following sequence:
Person request – This system takes a consumer enter resembling “The place is my order 123456?” from some shopper utility.
Plan subsequent motion(s) and choose device(s) to make use of – Subsequent, this system makes use of a immediate to have the LLM generate the subsequent motion, for instance, “Lookup the orders desk utilizing OrdersAPI.” The LLM is prompted to counsel a device identify resembling OrdersAPI from a predefined record of obtainable instruments and their descriptions. Alternatively, the LLM may very well be instructed to immediately generate an API name with enter parameters resembling OrdersAPI(12345).
Word that the subsequent motion could or could not contain utilizing a device or API. If not, the LLM would reply to consumer enter with out incorporating further context from instruments or just return a canned response resembling, “I can not reply this query.”
Parse device request – Subsequent, we have to parse out and validate the device/motion prediction steered by the LLM. Validation is required to make sure device names, APIs, and request parameters aren’t hallucinated and that the instruments are correctly invoked in line with specification. This parsing could require a separate LLM name.
Invoke device – As soon as legitimate device identify(s) and parameter(s) are ensured, we invoke the device. This may very well be an HTTP request, operate name, and so forth.
Parse output – The response from the device might have further processing. For instance, an API name could lead to an extended JSON response, the place solely a subset of fields are of curiosity to the LLM. Extracting info in a clear, standardized format may also help the LLM interpret the consequence extra reliably.
Interpret output – Given the output from the device, the LLM is prompted once more to make sense of it and determine whether or not it could generate the ultimate reply again to the consumer or whether or not further actions are required.
Terminate or proceed to step 2 – Both return a last reply or a default reply within the case of errors or timeouts.
Totally different agent frameworks execute the earlier program stream in another way. For instance, ReAct combines device choice and last reply technology right into a single immediate, versus utilizing separate prompts for device choice and reply technology. Additionally, this logic may be run in a single cross or run in a whereas assertion (the “agent loop”), which terminates when the ultimate reply is generated, an exception is thrown, or timeout happens. What stays fixed is that brokers use the LLM because the centerpiece to orchestrate planning and power invocations till the duty terminates. Subsequent, we present the way to implement a easy agent loop utilizing AWS providers.
Answer overview
For this weblog publish, we implement an e-commerce help LLM agent that gives two functionalities powered by instruments:
Return standing retrieval device – Reply questions concerning the standing of returns resembling, “What is going on to my return rtn001?”
Order standing retrieval device – Monitor the standing of orders resembling, “What’s the standing of my order 123456?”
The agent successfully makes use of the LLM as a question router. Given a question (“What’s the standing of order 123456?”), choose the suitable retrieval device to question throughout a number of knowledge sources (that’s, returns and orders). We accomplish question routing by having the LLM choose amongst a number of retrieval instruments, that are chargeable for interacting with a knowledge supply and fetching context. This extends the easy RAG sample, which assumes a single knowledge supply.
Each retrieval instruments are Lambda capabilities that take an id (orderId or returnId) as enter, fetches a JSON object from the info supply, and converts the JSON right into a human pleasant illustration string that’s appropriate for use by LLM. The info supply in a real-world situation may very well be a extremely scalable NoSQL database resembling DynamoDB, however this resolution employs easy Python Dict with pattern knowledge for demo functions.
Extra functionalities may be added to the agent by including Retrieval Instruments and modifying prompts accordingly. This agent may be examined a standalone service that integrates with any UI over HTTP, which may be achieved simply with Amazon Lex.

Listed here are some further particulars about the important thing parts:
LLM inference endpoint – The core of an agent program is an LLM. We are going to use SageMaker JumpStart basis mannequin hub to simply deploy the Flan-UL2 mannequin. SageMaker JumpStart makes it simple to deploy LLM inference endpoints to devoted SageMaker situations.
Agent orchestrator – Agent orchestrator orchestrates the interactions among the many LLM, instruments, and the shopper app. For our resolution, we use an AWS Lambda operate to drive this stream and make use of the next as helper capabilities.
Process (device) planner – Process planner makes use of the LLM to counsel one in every of 1) returns inquiry, 2) order inquiry, or 3) no device. We use immediate engineering solely and Flan-UL2 mannequin as-is with out fine-tuning.
Device parser – Device parser ensures that the device suggestion from activity planner is legitimate. Notably, we make sure that a single orderId or returnId may be parsed. In any other case, we reply with a default message.
Device dispatcher – Device dispatcher invokes instruments (Lambda capabilities) utilizing the legitimate parameters.
Output parser – Output parser cleans and extracts related objects from JSON right into a human-readable string. This activity is finished each by every retrieval device in addition to throughout the orchestrator.
Output interpreter – Output interpreter’s duty is to 1) interpret the output from device invocation and a pair of) decide whether or not the consumer request may be glad or further steps are wanted. If the latter, a last response is generated individually and returned to the consumer.
Now, let’s dive a bit deeper into the important thing parts: agent orchestrator, activity planner, and power dispatcher.
Agent orchestrator
Under is an abbreviated model of the agent loop contained in the agent orchestrator Lambda operate. The loop makes use of helper capabilities resembling task_planner or tool_parser, to modularize the duties. The loop right here is designed to run at most two instances to stop the LLM from being caught in a loop unnecessarily lengthy.
Process planner (device prediction)
The agent orchestrator makes use of activity planner to foretell a retrieval device based mostly on consumer enter. For our LLM agent, we’ll merely use immediate engineering and few shot prompting to show the LLM this activity in context. Extra subtle brokers may use a fine-tuned LLM for device prediction, which is past the scope of this publish. The immediate is as follows:
Device dispatcher
The device dispatch mechanism works through if/else logic to name applicable Lambda capabilities relying on the device’s identify. The next is tool_dispatch helper operate’s implementation. It’s used contained in the agent loop and returns the uncooked response from the device Lambda operate, which is then cleaned by an output_parser operate.
Deploy the answer
Vital conditions – To get began with the deployment, you could fulfill the next conditions:
Entry to the AWS Administration Console through a consumer who can launch AWS CloudFormation stacks
Familiarity with navigating the AWS Lambda and Amazon Lex consoles
Flan-UL2 requires a single ml.g5.12xlarge for deployment, which can necessitate rising useful resource limits through a help ticket. In our instance, we use us-east-1 because the Area, so please make certain to extend the service quota (if wanted) in us-east-1.
Deploy utilizing CloudFormation – You’ll be able to deploy the answer to us-east-1 by clicking the button beneath:![]()
Deploying the answer will take about 20 minutes and can create a LLMAgentStack stack, which:
deploys the SageMaker endpoint utilizing Flan-UL2 mannequin from SageMaker JumpStart;
deploys three Lambda capabilities: LLMAgentOrchestrator, LLMAgentReturnsTool, LLMAgentOrdersTool; and
deploys an AWS Lex bot that can be utilized to check the agent: Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Bot.
Take a look at the answer
The stack deploys an Amazon Lex bot with the identify Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Bot. The bot can be utilized to check the agent end-to-end. Right here’s an extra complete information for testing AWS Amazon Lex bots with a Lambda integration and the way the combination works at a excessive stage. However briefly, Amazon Lex bot is a useful resource that gives a fast UI to speak with the LLM agent working inside a Lambda operate that we constructed (LLMAgentOrchestrator).
The pattern take a look at circumstances to contemplate are as follows:
Legitimate order inquiry (for instance, “Which merchandise was ordered for 123456?”)
Order “123456” is a sound order, so we should always count on an affordable reply (e.g. “Natural Handsoap”)
Legitimate return inquiry for a return (for instance, “When is my return rtn003 processed?”)
We must always count on an affordable reply concerning the return’s standing.
Irrelevant to each returns or orders (for instance, “How is the climate in Scotland proper now?”)
An irrelevant query to returns or orders, thus a default reply must be returned (“Sorry, I can not reply that query.”)
Invalid order inquiry (for instance, “Which merchandise was ordered for 383833?”)
The id 383832 doesn’t exist within the orders dataset and therefore we should always fail gracefully (for instance, “Order not discovered. Please verify your Order ID.”)
Invalid return inquiry (for instance, “When is my return rtn123 processed?”)
Equally, id rtn123 doesn’t exist within the returns dataset, and therefore ought to fail gracefully.
Irrelevant return inquiry (for instance, “What’s the influence of return rtn001 on world peace?”)
This query, whereas it appears to pertain to a sound order, is irrelevant. The LLM is used to filter questions with irrelevant context.
To run these assessments your self, listed below are the directions.
On the Amazon Lex console (AWS Console > Amazon Lex), navigate to the bot entitled Sagemaker-Jumpstart-Flan-LLM-Agent-Fallback-Bot. This bot has already been configured to name the LLMAgentOrchestrator Lambda operate at any time when the FallbackIntent is triggered.
Within the navigation pane, select Intents.
Select Construct on the prime proper nook
4. Anticipate the construct course of to finish. When it’s achieved, you get a hit message, as proven within the following screenshot.
Take a look at the bot by coming into the take a look at circumstances.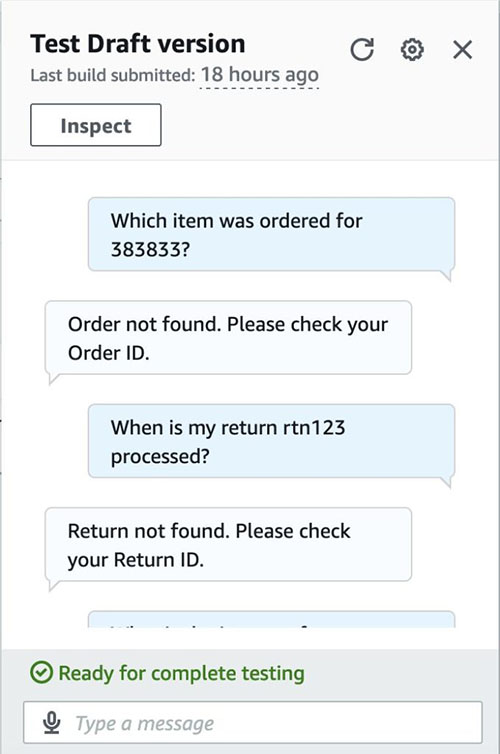
Cleanup
To keep away from further prices, delete the sources created by our resolution by following these steps:
On the AWS CloudFormation console, choose the stack named LLMAgentStack (or the customized identify you picked).
Select Delete
Verify that the stack is deleted from the CloudFormation console.
Vital: double-check that the stack is efficiently deleted by guaranteeing that the Flan-UL2 inference endpoint is eliminated.
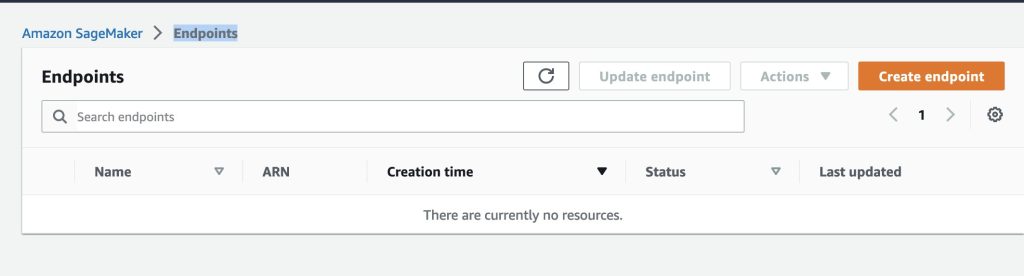
To verify, go to AWS console > Sagemaker > Endpoints > Inference web page.
The web page ought to record all energetic endpoints.
Make sure that sm-jumpstart-flan-bot-endpoint doesn’t exist just like the beneath screenshot.
Concerns for manufacturing
Deploying LLM brokers to manufacturing requires taking additional steps to make sure reliability, efficiency, and maintainability. Listed here are some issues previous to deploying brokers in manufacturing:
Deciding on the LLM mannequin to energy the agent loop: For the answer mentioned on this publish, we used a Flan-UL2 mannequin with out fine-tuning to carry out activity planning or device choice. In observe, utilizing an LLM that’s fine-tuned to immediately output device or API requests can enhance reliability and efficiency, in addition to simplify growth. We may fine-tune an LLM on device choice duties or use a mannequin that immediately decodes device tokens like Toolformer.
Utilizing fine-tuned fashions can even simplify including, eradicating, and updating instruments obtainable to an agent. With prompt-only based mostly approaches, updating instruments requires modifying each immediate contained in the agent orchestrator, resembling these for activity planning, device parsing, and power dispatch. This may be cumbersome, and the efficiency could degrade if too many instruments are offered in context to the LLM.
Reliability and efficiency: LLM brokers may be unreliable, particularly for complicated duties that can not be accomplished inside a couple of loops. Including output validations, retries, structuring outputs from LLMs into JSON or yaml, and implementing timeouts to supply escape hatches for LLMs caught in loops can improve reliability.
Conclusion
On this publish, we explored the way to construct an LLM agent that may make the most of a number of instruments from the bottom up, utilizing low-level immediate engineering, AWS Lambda capabilities, and SageMaker JumpStart as constructing blocks. We mentioned the structure of LLM brokers and the agent loop intimately. The ideas and resolution structure launched on this weblog publish could also be applicable for brokers that use a small variety of a predefined set of instruments. We additionally mentioned a number of methods for utilizing brokers in manufacturing. Brokers for Bedrock, which is in preview, additionally supplies a managed expertise for constructing brokers with native help for agentic device invocations.
Concerning the Creator
 John Hwang is a Generative AI Architect at AWS with particular concentrate on Giant Language Mannequin (LLM) functions, vector databases, and generative AI product technique. He’s obsessed with serving to firms with AI/ML product growth, and the way forward for LLM brokers and co-pilots. Previous to becoming a member of AWS, he was a Product Supervisor at Alexa, the place he helped deliver conversational AI to cellular units, in addition to a derivatives dealer at Morgan Stanley. He holds B.S. in pc science from Stanford College.
John Hwang is a Generative AI Architect at AWS with particular concentrate on Giant Language Mannequin (LLM) functions, vector databases, and generative AI product technique. He’s obsessed with serving to firms with AI/ML product growth, and the way forward for LLM brokers and co-pilots. Previous to becoming a member of AWS, he was a Product Supervisor at Alexa, the place he helped deliver conversational AI to cellular units, in addition to a derivatives dealer at Morgan Stanley. He holds B.S. in pc science from Stanford College.








/cdn.vox-cdn.com/uploads/chorus_asset/file/24016883/STK093_Google_06.jpg "Google to pay California million over location-tracking claims")

")

")









")

{kind=link}