

Regardless of the seemingly unstoppable adoption of LLMs throughout industries, they’re one part of a broader know-how ecosystem that’s powering the brand new AI wave. Many conversational AI use instances require LLMs like Llama 2, Flan T5, and Bloom to reply to consumer queries. These fashions depend on parametric data to reply questions. The mannequin learns this data throughout coaching and encodes it into the mannequin parameters. With the intention to replace this data, we should retrain the LLM, which takes loads of money and time.
Luckily, we are able to additionally use supply data to tell our LLMs. Supply data is info fed into the LLM by an enter immediate. One well-liked strategy to offering supply data is Retrieval Augmented Technology (RAG). Utilizing RAG, we retrieve related info from an exterior information supply and feed that info into the LLM.
On this weblog put up, we’ll discover the way to deploy LLMs resembling Llama-2 utilizing Amazon Sagemaker JumpStart and maintain our LLMs updated with related info by Retrieval Augmented Technology (RAG) utilizing the Pinecone vector database with a purpose to forestall AI Hallucination.
Retrieval Augmented Technology (RAG) in Amazon SageMaker
Pinecone will deal with the retrieval part of RAG, however you want two extra crucial parts: someplace to run the LLM inference and someplace to run the embedding mannequin.
Amazon SageMaker Studio an built-in growth setting (IDE) that gives a single web-based visible interface the place you’ll be able to entry purpose-built instruments to carry out all machine studying (ML) growth. It offers SageMaker JumpStart which is a mannequin hub the place customers can find, preview, and launch a specific mannequin in their very own SageMaker account. It offers pretrained, publicly obtainable and proprietary fashions for a variety of downside sorts, together with Basis Fashions.
Amazon SageMaker Studio offers the best setting for creating RAG-enabled LLM pipelines. First, utilizing the AWS console, go to Amazon SageMaker & create a SageMaker Studio area and open a Jupyter Studio pocket book.
Stipulations
Full the next prerequisite steps:
Arrange Amazon SageMaker Studio.
Onboard to an Amazon SageMaker Area.
Join a free-tier Pinecone Vector Database.
Prerequisite libraries: SageMaker Python SDK, Pinecone Shopper
Answer Walkthrough
Utilizing SageMaker Studio pocket book, we first want set up prerequisite libraries:
Deploying an LLM
On this put up, we focus on two approaches to deploying an LLM. The primary is thru the HuggingFaceModel object. You should use this when deploying LLMs (and embedding fashions) instantly from the Hugging Face mannequin hub.
For instance, you’ll be able to create a deployable config for the google/flan-t5-xl mannequin as proven within the following display seize:
When deploying fashions instantly from Hugging Face, initialize the my_model_configuration with the next:
An env config tells us which mannequin we wish to use and for what job.
Our SageMaker execution function provides us permissions to deploy our mannequin.
An image_uri is a picture config particularly for deploying LLMs from Hugging Face.
Alternatively, SageMaker has a set of fashions instantly suitable with a less complicated JumpStartModel object. Many well-liked LLMs like Llama 2 are supported by this mannequin, which may be initialized as proven within the following display seize:
For each variations of my_model, deploy them as proven within the following display seize:
With our initialized LLM endpoint, you’ll be able to start querying. The format of our queries could fluctuate (notably between conversational and non-conversational LLMs), however the course of is usually the identical. For the Hugging Face mannequin, do the next:
Yow will discover the answer within the GitHub repository.
The generated reply we’re receiving right here doesn’t make a lot sense — it’s a hallucination.
Offering Further Context to LLM
Llama 2 makes an attempt to reply our query primarily based solely on inner parametric data. Clearly, the mannequin parameters don’t retailer data of which situations we are able to with managed spot coaching in SageMaker.
To reply this query accurately, we should use supply data. That’s, we give further info to the LLM through the immediate. Let’s add that info instantly as further context for the mannequin.
We now see the right reply to the query; that was simple! Nonetheless, a consumer is unlikely to insert contexts into their prompts, they’d already know the reply to their query.
Moderately than manually inserting a single context, routinely determine related info from a extra intensive database of knowledge. For that, you’ll need Retrieval Augmented Technology.
Retrieval Augmented Technology
With Retrieval Augmented Technology, you’ll be able to encode a database of knowledge right into a vector area the place the proximity between vectors represents their relevance/semantic similarity. With this vector area as a data base, you’ll be able to convert a brand new consumer question, encode it into the identical vector area, and retrieve essentially the most related information beforehand listed.
After retrieving these related information, choose a couple of of them and embody them within the LLM immediate as further context, offering the LLM with extremely related supply data. It is a two-step course of the place:
Indexing populates the vector index with info from a dataset.
Retrieval occurs throughout a question and is the place we retrieve related info from the vector index.
Each steps require an embedding mannequin to translate our human-readable plain textual content into semantic vector area. Use the extremely environment friendly MiniLM sentence transformer from Hugging Face as proven within the following display seize. This mannequin shouldn’t be an LLM and subsequently shouldn’t be initialized in the identical means as our Llama 2 mannequin.
Within the hub_config, specify the mannequin ID as proven within the display seize above however for the duty, use feature-extraction as a result of we’re producing vector embeddings not textual content like our LLM. Following this, initialize the mannequin config with HuggingFaceModel as earlier than, however this time with out the LLM picture and with some model parameters.
You possibly can deploy the mannequin once more with deploy, utilizing the smaller (CPU solely) occasion of ml.t2.giant. The MiniLM mannequin is tiny, so it doesn’t require loads of reminiscence and doesn’t want a GPU as a result of it will probably shortly create embeddings even on a CPU. If most popular, you’ll be able to run the mannequin sooner on GPU.
To create embeddings, use the predict technique and go a listing of contexts to encode through the inputs key as proven:
Two enter contexts are handed, returning two context vector embeddings as proven:
len(out)
2
The embedding dimensionality of the MiniLM mannequin is 384 which implies every vector embedding MiniLM outputs ought to have a dimensionality of 384. Nonetheless, wanting on the size of our embeddings, you will notice the next:
len(out[0]), len(out[1])
(8, 8)
Two lists comprise eight objects every. MiniLM first processes textual content in a tokenization step. This tokenization transforms our human-readable plain textual content into a listing of model-readable token IDs. Within the output options of the mannequin, you’ll be able to see the token-level embeddings. one in every of these embeddings exhibits the anticipated dimensionality of 384 as proven:
len(out[0][0])
384
Rework these token-level embeddings into document-level embeddings by utilizing the imply values throughout every vector dimension, as proven within the following illustration.
Imply pooling operation to get a single 384-dimensional vector.
With two 384-dimensional vector embeddings, one for every enter textual content. To make our lives simpler, wrap the encoding course of right into a single perform as proven within the following display seize:
Downloading the Dataset
Obtain the Amazon SageMaker FAQs because the data base to get the info which incorporates each query and reply columns.
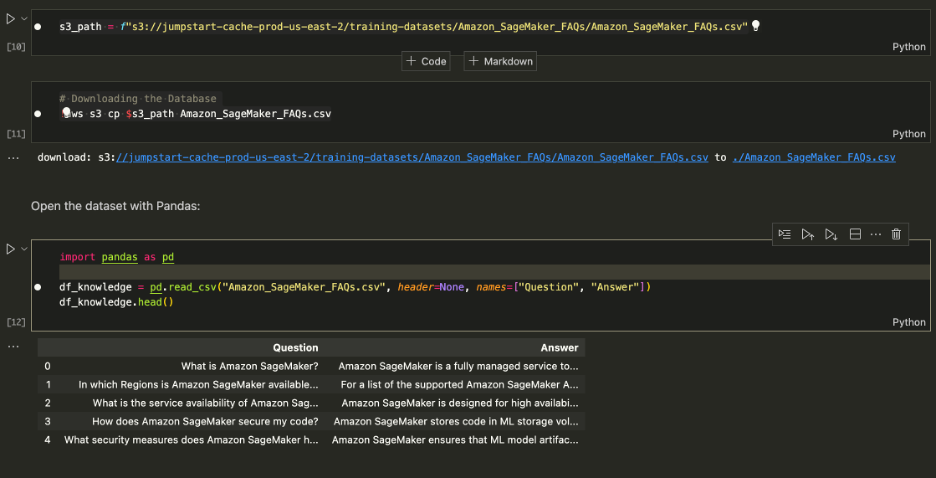
Obtain the Amazon SageMaker FAQs
When performing the search, search for Solutions solely, so you’ll be able to drop the Query column. See pocket book for particulars.
Our dataset and the embedding pipeline are prepared. Now all we’d like is someplace to retailer these embeddings.
Indexing
The Pinecone vector database shops vector embeddings and searches them effectively at scale. To create a database, you’ll need a free API key from Pinecone.
After you may have related to the Pinecone vector database, create a single vector index (just like a desk in conventional DBs). Title the index retrieval-augmentation-aws and align the index dimension and metric parameters with these required by the embedding mannequin (MiniLM on this case).
To start inserting information, run the next:
You possibly can start querying the index with the query from earlier on this put up.
Above output exhibits that we’re returning related contexts to assist us reply our query. Since we top_k = 1, index.question returned the highest end result alongside facet the metadata which reads Managed Spot Coaching can be utilized with all situations supported in Amazon.
Augmenting the Immediate
Use the retrieved contexts to enhance the immediate and determine on a most quantity of context to feed into the LLM. Use the 1000 characters restrict to iteratively add every returned context to the immediate till you exceed the content material size.
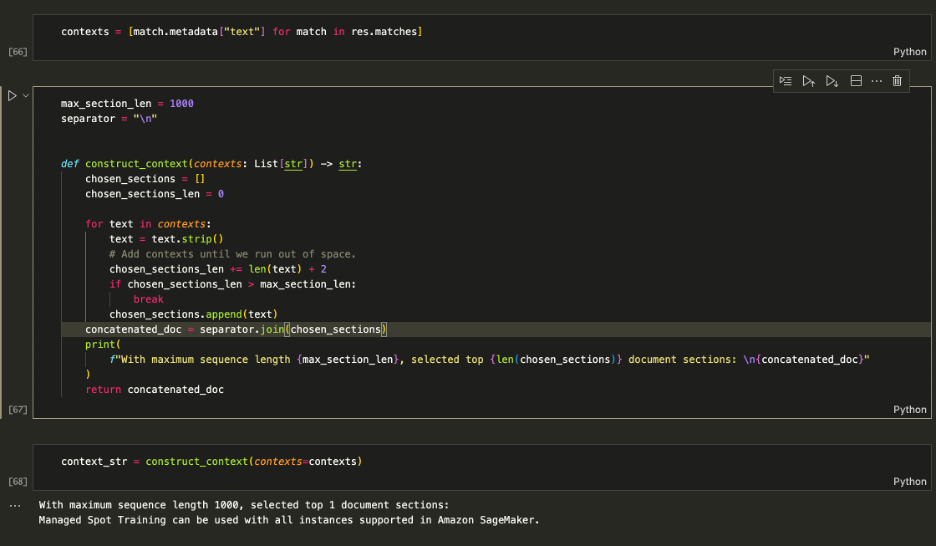
Augmenting the Immediate
Feed the context_str into the LLM immediate as proven within the following display seize:
[Input]: Which situations can I take advantage of with Managed Spot Coaching in SageMaker?
[Output]: Primarily based on the context supplied, you should utilize Managed Spot Coaching with all situations supported in Amazon SageMaker. Due to this fact, the reply is:
All situations supported in Amazon SageMaker.
The logic works, so wrap it up right into a single perform to maintain issues clear.
Now you can ask questions like these proven within the following:
Clear up
To cease incurring any undesirable expenses, delete the mannequin and endpoint.
Conclusion
On this put up, we launched you to RAG with open-access LLMs on SageMaker. We additionally confirmed the way to deploy Amazon SageMaker Jumpstart fashions with Llama 2, Hugging Face LLMs with Flan T5, and embedding fashions with MiniLM.
We carried out a whole end-to-end RAG pipeline utilizing our open-access fashions and a Pinecone vector index. Utilizing this, we confirmed the way to decrease hallucinations, and maintain LLM data updated, and in the end improve the consumer expertise and belief in our techniques.
To run this instance by yourself, clone this GitHub repository and walkthrough the earlier steps utilizing the Query Answering pocket book on GitHub.
Concerning the authors
 Vedant Jain is a Sr. AI/ML Specialist, engaged on strategic Generative AI initiatives. Previous to becoming a member of AWS, Vedant has held ML/Information Science Specialty positions at numerous corporations resembling Databricks, Hortonworks (now Cloudera) & JP Morgan Chase. Exterior of his work, Vedant is enthusiastic about making music, mountain climbing, utilizing science to guide a significant life & exploring cuisines from around the globe.
Vedant Jain is a Sr. AI/ML Specialist, engaged on strategic Generative AI initiatives. Previous to becoming a member of AWS, Vedant has held ML/Information Science Specialty positions at numerous corporations resembling Databricks, Hortonworks (now Cloudera) & JP Morgan Chase. Exterior of his work, Vedant is enthusiastic about making music, mountain climbing, utilizing science to guide a significant life & exploring cuisines from around the globe.
 James Briggs is a Employees Developer Advocate at Pinecone, specializing in vector search and AI/ML. He guides builders and companies in creating their very own GenAI options by on-line training. Previous to Pinecone James labored on AI for small tech startups to established finance companies. Exterior of labor, James has a ardour for touring and embracing new adventures, starting from browsing and scuba to Muay Thai and BJJ.
James Briggs is a Employees Developer Advocate at Pinecone, specializing in vector search and AI/ML. He guides builders and companies in creating their very own GenAI options by on-line training. Previous to Pinecone James labored on AI for small tech startups to established finance companies. Exterior of labor, James has a ardour for touring and embracing new adventures, starting from browsing and scuba to Muay Thai and BJJ.
 Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on creating scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular information, and strong evaluation of non-parametric space-time clustering. He has printed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Collection A.
Xin Huang is a Senior Utilized Scientist for Amazon SageMaker JumpStart and Amazon SageMaker built-in algorithms. He focuses on creating scalable machine studying algorithms. His analysis pursuits are within the space of pure language processing, explainable deep studying on tabular information, and strong evaluation of non-parametric space-time clustering. He has printed many papers in ACL, ICDM, KDD conferences, and Royal Statistical Society: Collection A.






")



")

")












{kind=link}