

Giant Language Fashions (LLMs) have turn out to be important instruments in numerous domains as a consequence of their distinctive skill to know and generate human language. These fashions, which regularly include billions of parameters, require intensive computational sources for coaching and fine-tuning. The first problem lies in effectively managing the reminiscence and computational calls for to make these fashions accessible to varied customers & functions.
Coaching LLMs are inherently memory-intensive, necessitating substantial {hardware} sources which can be solely available to some customers. Conventional strategies demand massive reminiscence allocations to deal with the quite a few parameters and optimization states. As an illustration, coaching a LLaMA 7B mannequin from scratch usually requires round 58 GB of reminiscence, together with 14 GB for trainable parameters, 42 GB for Adam optimizer states and weight gradients, and a couple of GB for activation. This excessive reminiscence requirement poses a major barrier to entry for a lot of researchers and builders who want entry to superior {hardware} setups.
Numerous methods have been developed to handle this drawback. These embrace designing smaller-scale LLMs, using environment friendly scaling methods, and incorporating sparsity into the coaching methodologies. Amongst these, GaLore has emerged as a notable technique, permitting for the full-parameter coaching of LLMs by way of low-rank gradient updates utilizing Singular Worth Decomposition (SVD). GaLore reduces reminiscence utilization by as much as 63.3%, enabling coaching a 7B mannequin with simply 24GB of reminiscence. Nonetheless, GaLore nonetheless requires extra reminiscence than is out there on many generally used gadgets, corresponding to well-liked laptop computer GPUs just like the RTX 4060 Ti, which have as much as 16GB of reminiscence.
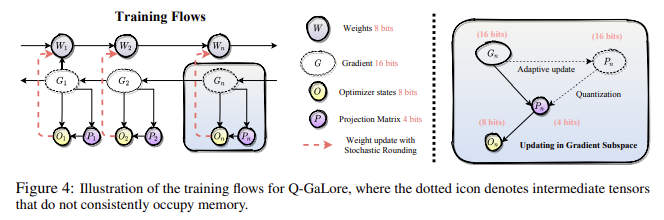
Researchers from the College of Texas at Austin, the College of Surrey, the College of Oxford, the California Institute of Expertise, and Meta AI have launched Q-GaLore to cut back reminiscence consumption additional and make LLM coaching extra accessible. Q-GaLore combines quantization and low-rank projection to boost reminiscence effectivity considerably. This technique builds on two key observations: the gradient subspace reveals various properties, with some layers stabilizing early in coaching. In distinction, others change steadily, and the projection matrices are extremely resilient to low-bit quantization. By leveraging these insights, Q-GaLore adaptively updates the gradient subspace based mostly on convergence statistics, sustaining efficiency whereas lowering the variety of SVD operations. The mannequin weights are stored in INT8 format, and the projection matrices are in INT4 format, which conserves reminiscence aggressively.
Q-GaLore employs two most important modules: low-precision coaching with low-rank gradients and lazy layer-wise subspace exploration. Your complete mannequin, together with optimizer states, makes use of 8-bit precision for the Adam optimizer, and the projection matrices are quantized to 4 bits. This method ends in a reminiscence discount of roughly 28.57% for gradient low-rank coaching. Stochastic rounding maintains coaching stability and approximates the high-precision coaching trajectory. This technique permits for a high-precision coaching path utilizing solely low-precision weights, preserving small gradient contributions successfully without having to keep up high-precision parameters.
In sensible functions, Q-GaLore has carried out exceptionally in pre-training and fine-tuning eventualities. Throughout pre-training, Q-GaLore enabled the coaching of an LLaMA-7B mannequin from scratch on a single NVIDIA RTX 4060 Ti with solely 16GB of reminiscence. This can be a vital achievement, demonstrating the strategy’s distinctive reminiscence effectivity and practicality. In fine-tuning duties, Q-GaLore diminished reminiscence consumption by as much as 50% in comparison with different strategies like LoRA and GaLore whereas constantly outperforming QLoRA by as much as 5.19 on MMLU benchmarks on the similar reminiscence price.
Q-GaLore’s efficiency and effectivity have been evaluated throughout numerous mannequin sizes, from 60 million to 7 billion parameters. For a 1 billion parameter mannequin, Q-GaLore maintained comparable pre-training efficiency with lower than a 0.84 enhance in perplexity in comparison with the unique GaLore technique whereas reaching a 29.68% reminiscence saving in opposition to GaLore and a 60.51% reminiscence saving in comparison with the total baseline. Notably, Q-GaLore facilitated the pre-training of a 7B mannequin inside a 16GB reminiscence constraint, reaching a perplexity distinction of lower than one in comparison with the baseline fashions.

In conclusion, Q-GaLore gives a sensible answer to the reminiscence constraints historically related to these fashions within the environment friendly coaching of LLMs. By combining quantization and low-rank projection, Q-GaLore achieves aggressive efficiency and broadens the accessibility of highly effective language fashions. This technique highlights the potential for optimizing large-scale fashions for extra generally obtainable {hardware} configurations, making cutting-edge language processing applied sciences extra accessible to a wider viewers.
Try the Paper and GitHub. All credit score for this analysis goes to the researchers of this venture. Additionally, don’t neglect to comply with us on Twitter.
Be a part of our Telegram Channel and LinkedIn Group.
When you like our work, you’ll love our publication..
Don’t Neglect to affix our 46k+ ML SubReddit
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.







")


")
")







")




{kind=link}