

Transformers have taken over from recurrent neural networks (RNNs) as the popular structure for pure language processing (NLP). Transformers stand out conceptually as a result of they straight entry every token in a sequence, not like RNNs that depend on sustaining a recurring state of previous inputs. Decoders have emerged as a distinguished variant inside the realm of transformers. These decoders generally produce output in an auto-regressive method, that means the technology of every token is influenced by the important thing and worth computations of previous tokens.
Researchers from The Hebrew College of Jerusalem and FAIR, AI at Meta, have demonstrated that the auto-regressive nature of transformers aligns with the basic precept of RNNs, which entails preserving a state from one step to the following. They formally redefine decoder-only transformers as multi-state RNNs (MSRNN), presenting a generalized model of conventional RNNs. This redefinition highlights that because the variety of earlier tokens will increase throughout decoding, transformers grow to be MSRNNs with infinite states. The researchers additional present that transformers could be compressed into finite MSRNNs by limiting the variety of tokens processed at every step. They introduce TOVA, a compression coverage for MSRNNs, which selects tokens to retain based mostly solely on their consideration scores. The analysis of TOVA is carried out on 4 long-range duties.
The research compares transformers and RNNs, demonstrating that decoder-only transformers could be conceptualized as infinite multi-state RNNs, and pretrained transformers could be transformed into finite multi-state RNNs by fixing the dimensions of their hidden state. It stories perplexity on the PG-19 take a look at set for language modeling. It makes use of take a look at units from the ZeroSCROLLS benchmark for evaluating long-range understanding, together with long-range summarization and long-range question-answering duties. The research mentions utilizing the QASPER dataset for lengthy textual content query answering and evaluating generated tales utilizing GPT-4 as an evaluator.
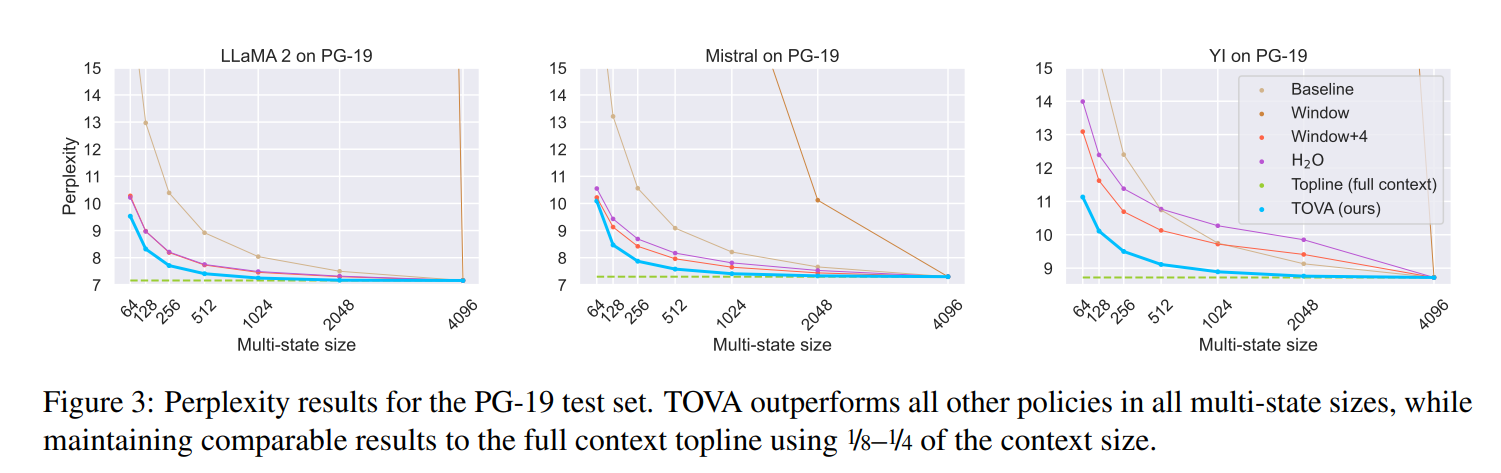
The research demonstrates that decoder-only transformers could be conceptualized as infinite multi-state RNNs, and pretrained transformers could be transformed into finite multi-state RNNs by fixing the dimensions of their hidden state. The research additionally mentions modifying the eye masks to include totally different MSRNN insurance policies, such because the First In First Out (FIFO) technique, to successfully parallel the language modeling process. The researchers use the GPT-4 mannequin to judge the generated texts and evaluate the output of the TOVA coverage with the topline mannequin.
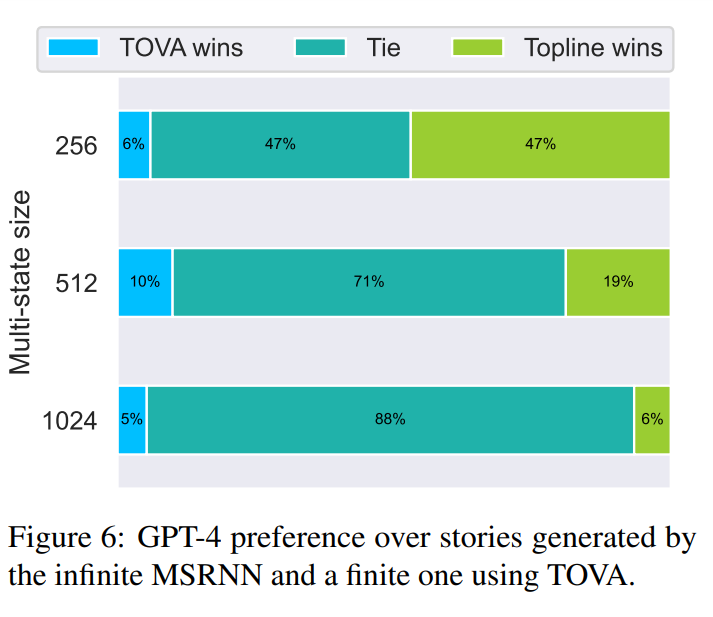
The research demonstrates that transformer decoder LLMs behave as finite MSRNNs although they’re educated as infinite MSRNNs. The proposed TOVA coverage performs persistently higher than different insurance policies in long-range duties with smaller cache sizes throughout all multi-state sizes and fashions. The experiments present that utilizing TOVA with 1 / 4 and even one-eighth of the complete context yields outcomes inside one level of the topline mannequin in language modeling duties. The research additionally stories a big discount in LLM cache measurement, as much as 88%, resulting in diminished reminiscence consumption throughout inference. The researchers acknowledge the computational constraints and approximate the infinite MSRNN with a sequence size of 4,096 tokens for extrapolation experiments.
To summarize, the researchers have redefined decoder transformers as multi-state RNNs with an infinite multi-state measurement. When the variety of token representations that transformers can deal with at every step is restricted, it’s the identical as compressing it from infinite to finite MSRNNs. The TOVA coverage, which is a straightforward compression methodology that selects which tokens to maintain utilizing their consideration scores, has been discovered to outperform current compression insurance policies and performs comparably to the infinite MSRNN mannequin with a diminished multi-state measurement. Though not educated, transformers usually operate as finite MSRNNs in observe. These findings present insights into the inter-working of transformers and their connections to RNNs. Additionally, they’ve sensible worth in lowering the LLM cache measurement by as much as 88%.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this challenge. Additionally, don’t neglect to observe us on Twitter. Be a part of our 36k+ ML SubReddit, 41k+ Fb Group, Discord Channel, and LinkedIn Group.
In case you like our work, you’ll love our publication..
Don’t Neglect to hitch our Telegram Channel
![]()
Sana Hassan, a consulting intern at Marktechpost and dual-degree scholar at IIT Madras, is captivated with making use of expertise and AI to handle real-world challenges. With a eager curiosity in fixing sensible issues, he brings a recent perspective to the intersection of AI and real-life options.










")

")






")




{kind=link}