

Emergent talents in massive language fashions (LLMs) consult with capabilities current in bigger fashions however absent in smaller ones, a foundational idea that has guided prior analysis. Whereas research have recognized 67 such emergent talents by benchmark evaluations, some researchers query whether or not these are real or merely artifacts of the analysis strategies used. In response, different works argue that sure talents are certainly emergent, as LLMs outperform smaller fashions on particular duties. Investigations into the roles of reminiscence and in-context studying (ICL) goal to elucidate the mechanisms behind LLM efficiency. Nevertheless, earlier evaluations haven’t clearly differentiated between ICL and instruction-tuning settings, an vital distinction for understanding the true nature of emergent talents. This paper seeks to handle these gaps within the literature.
Researchers from the Technical College of Darmstadt and The College of Bathtub current a brand new concept explaining emergent talents in massive language fashions (LLMs). LLMs, with their many parameters and enormous coaching datasets, typically exhibit sudden abilities often called “emergent talents.” Nevertheless, these talents are sometimes confused with abilities gained by completely different prompting strategies, akin to in-context studying, the place fashions be taught from examples. The analysis, supported by over 1000 experiments, reveals that these talents usually are not actually emergent however fairly stem from a mixture of in-context studying, reminiscence, and language information fairly than being innate.
Pre-trained language fashions (PLMs) excel at studying language guidelines however wrestle with real-world language use, which requires extra advanced understanding. LLMs, being bigger variations of PLMs, reveal higher efficiency on duties with out particular coaching, suggesting they’ve emergent talents. Nevertheless, the examine argues that profitable activity efficiency by methods like in-context studying and instruction-tuning doesn’t imply the mannequin has an inherent capability. The analysis goals to make clear which talents are genuinely emergent and the way a lot in-context studying influences LLM efficiency, guaranteeing their secure and efficient use in numerous functions.
The first goal of this examine was to research whether or not the emergent talents noticed in massive language fashions (LLMs) are genuinely emergent or could be attributed to in-context studying (ICL) and different mannequin competencies. The researchers chosen a various set of duties, primarily from the BIG-bench dataset, to comprehensively consider the capabilities of fashions like GPT-3 and Flan-T5-large. The analysis course of concerned assessing the fashions’ efficiency throughout 21 completely different duties, specializing in figuring out instances the place they considerably outperformed random baselines.
A guide analysis of fifty examples per activity was carried out to make sure the accuracy and high quality of the outputs. The researchers employed statistical strategies to analyse the efficiency information, evaluating the outcomes of instruction-tuned and non-instruction-tuned fashions to know the affect of ICL and different elements on the noticed talents. Moreover, the researchers used an “adversarial immediate setting” to check the fashions’ capabilities in a extra managed method. The findings from this systematic method goal to contribute to a deeper understanding of LLMs’ talents and limitations, addressing security issues associated to their use.
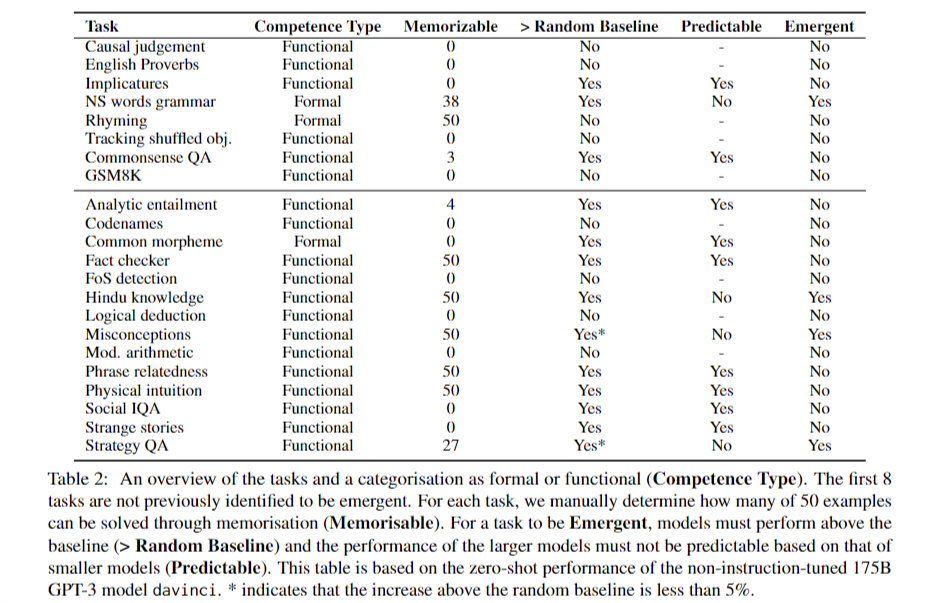
The examine evaluated the efficiency of assorted massive language fashions (LLMs) throughout 22 duties, revealing that whereas some fashions carried out above the random baseline, the enhancements had been typically modest and never indicative of true emergent talents. Solely 5 out of the 21 duties confirmed important efficiency variations between fashions, suggesting that instruction-tuning performs a vital function in enhancing mannequin capabilities. The comparative evaluation highlighted the overlapping efficiency of fashions like Flan-T5-large and GPT-J, indicating that instruction-tuning could allow fashions to leverage in-context studying extra successfully fairly than revealing inherent emergent reasoning talents.
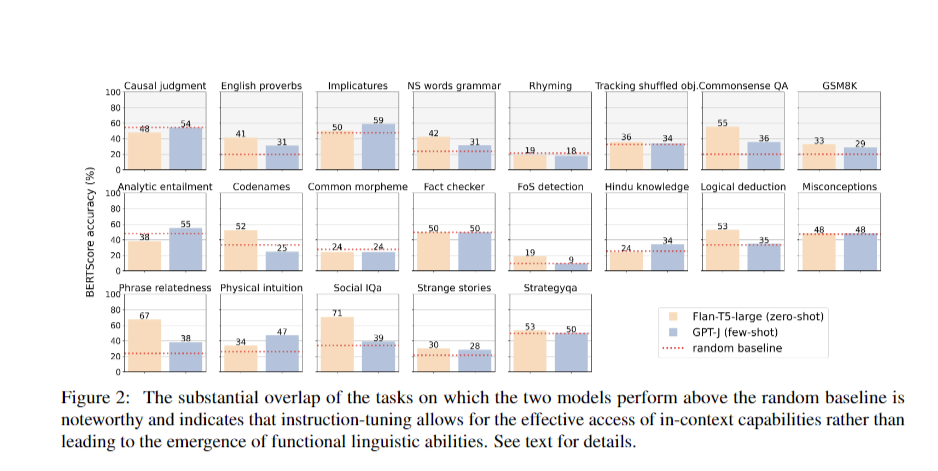
The guide analysis of responses additional revealed that many duties remained predictable based mostly on smaller mannequin performances, suggesting that the noticed enhancements don’t essentially mirror emergent talents however fairly the fashions’ reliance on realized patterns and directions. Throughout the varied mannequin households examined, a constant sample emerged: both the duty efficiency was predictable based mostly on smaller fashions, or it fell under the baseline. This discovering reinforces the notion that the capabilities of LLMs shouldn’t be overestimated, as their efficiency typically aligns with realized competencies fairly than true emergent reasoning.
In conclusion, this examine finds that the so-called emergent talents of huge language fashions (LLMs) usually are not actually emergent however fairly stem primarily from in-context studying (ICL), mannequin reminiscence, and linguistic information. By way of in depth experimentation, the authors reveal that LLM efficiency is usually predictable based mostly on smaller fashions or falls under baseline, difficult the notion of sturdy emergent talents. Whereas instruction-tuning enhances the fashions’ capability to observe directions, the authors emphasize this doesn’t equate to reasoning capabilities, as evidenced by ‘hallucination.’ To deal with security issues, the examine underscores the significance of understanding LLMs’ limitations and advocates creating detection mechanisms and moral pointers to mitigate dangers. This analysis lays the groundwork for refining the understanding and secure, moral software of LLMs.
Try the Paper. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t overlook to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Should you like our work, you’ll love our publication..
Don’t Neglect to hitch our 49k+ ML SubReddit
Discover Upcoming AI Webinars right here

Shoaib Nazir is a consulting intern at MarktechPost and has accomplished his M.Tech twin diploma from the Indian Institute of Expertise (IIT), Kharagpur. With a robust ardour for Knowledge Science, he’s notably within the various functions of synthetic intelligence throughout numerous domains. Shoaib is pushed by a need to discover the newest technological developments and their sensible implications in on a regular basis life. His enthusiasm for innovation and real-world problem-solving fuels his steady studying and contribution to the sphere of AI










")

")







")




{kind=link}